AGI progress has stalled.
New ideas are needed.


ARC Prize Survives 3 months
Bigger Prizes, New Events, Benchmark Improvements
ARC Prize is a nonprofit dedicated to advancing open artificial general intelligence (AGI).
We launched ARC Prize to provide the world a measure of progress towards AGI and hopefully inspire more AI researchers to openly work on new AGI ideas.
We are 3 months into the 2024 competition. ARC Prize is still unbeaten.
Millions of people are now aware of ARC Prize. ARC Prize is the #1 competition on Kaggle. One thousand teams are making one thousand submissions every week. ARC-AGI has been mentioned in notable publications like TIME, Semafor, Reuters, and New Scientist, along with dozens of podcasts including Dwarkesh, Sean Carroll's Mindscape, and Tucker Carlson.
When new state-of-the-art LLM models are released, people are starting to ask how it performs on ARC-AGI. Over half a million people caught the ARC-AGI-Pub results we published for OpenAI's o1 models.

Today we're announcing a bigger Grand Prize (now $600k), bigger and more Paper Awards (now $75k), and we're committing funds for a US university tour in October and the development of the next iteration of ARC-AGI.
3-Month Update
ARC Prize is a grand experiment. The ARC-AGI benchmark was conceptualized in 2017, published in 2019, and remains unbeaten as of September 2024. We launched ARC Prize this June with a state-of-the-art (SOTA) score of 34%. Progress had been decelerating.
The competition kicked off with the hypothesis that new ideas are needed to unlock AGI and we put over $1,000,000 on the line to prove it wrong. When we launched, we said that if the benchmark remained unbeaten after 3 months we'd increase the prize.
Since launch, new approaches hit the leaderboards resulting in a 12pp score increase to the 46% SOTA!
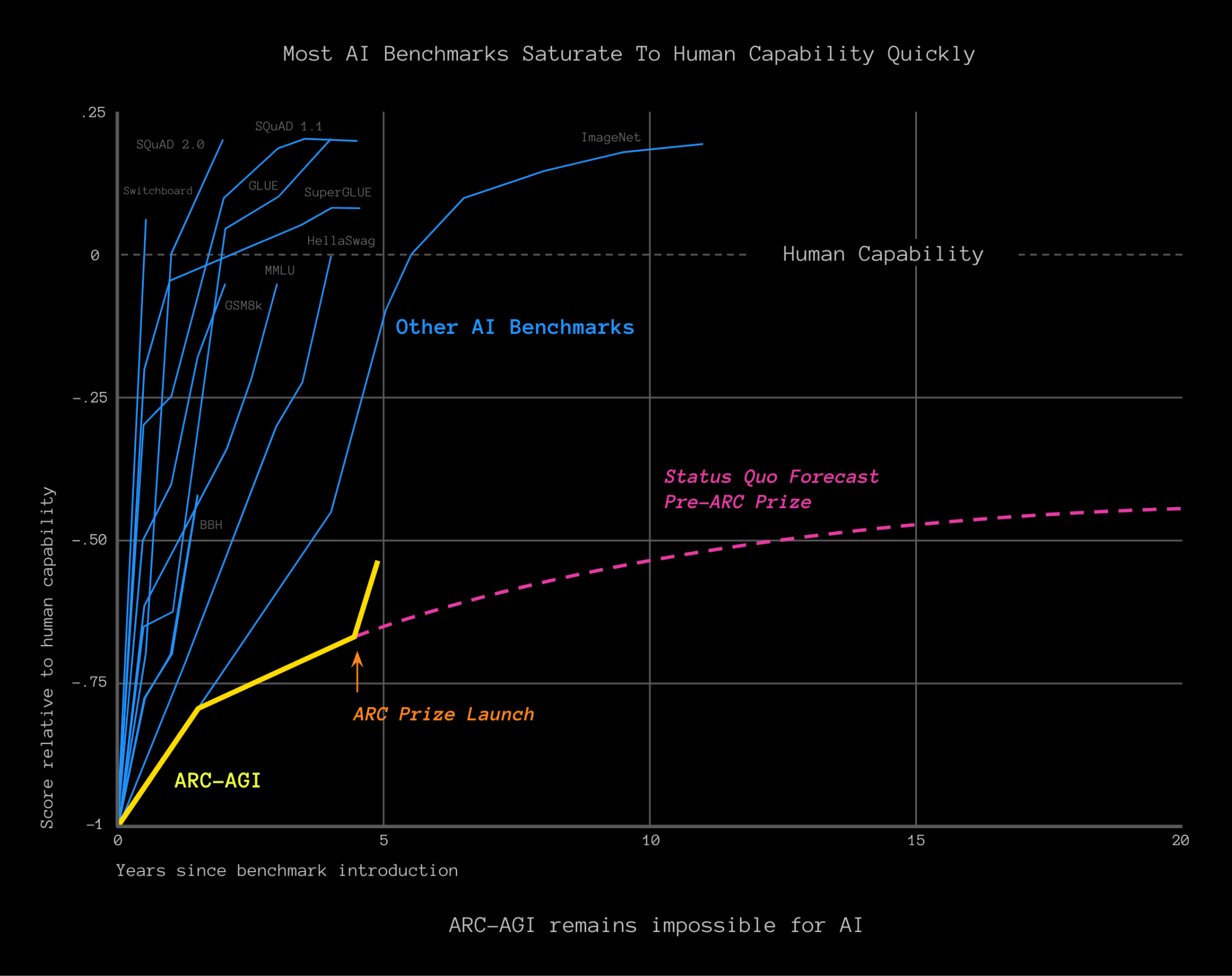
ARC Prize is changing the trajectory of open AGI progress. But so far, no one has claimed the Grand Prize.
We Still Need New Ideas!
We can now more confidently say that existing approaches are insufficient to defeat ARC-AGI. The large prize efficiently clears the idea space of low hanging fruit.
The benchmark continues to resist all known solutions, including expensive, scaled-up LLM solutions and newly released models that emulate human reasoning. This is not just evidence that we need to try new things, it's also evidence the underlying concepts of ARC-AGI are correct; specifically, Chollet's definition of AGI:
AGI is a system that can efficiently acquire skill and apply it towards open-ended tasks.
While many were skeptical on Launch Day, over the past few months, tens of thousands of people have attempted the puzzles on arcprize.org and we consistently hear, "I'm surprised AI can't do this!"
While not perfect, ARC-AGI is still the only benchmark that was designed to resist memorization - the very thing LLMs are superhuman at - and measures progress to close the gap between current AI and AGI.
The current leading approach from the MindsAI team involves fine-tuning a language model at test-time on a generated dataset to achieve their 46% score. On the public leaderboard, the top approach leverages parallel inference and search to achieve a 43% score. These techniques are similar to the closed source AGI research by larger, well-funded AI labs like DeepMind, OpenAI, DeepSeek, and others.
By the end of ARC Prize 2024 we expect to publish several novel open source implementations to help propel the scientific frontier forward.
But we need to go further. We still seem to be missing something big and important. There are only a few teams competitive on the leaderboard and today's approaches alone will not reach the Grand Prize goal. We need more exploration from more people.
Key Challenges
The mission of ARC Prize is to accelerate open progress towards AGI. We see 3 challenges towards this goal.
1. There are too few new conceptual breakthroughs.
The novel research that is succeeding on ARC Prize is similar to frontier AGI lab closed approaches. As exciting as that progress is, it seems insufficient to reach the 85% goal.
To reach AGI we need new thinking on how to use deep learning to better guide discrete search. To solve problems, humans don't deterministically check thousands of programs, we use our intuition to shrink the search space to just a handful. Have any ideas here?
We also need new ways to imbue program synthesis engines with goal and sub-goal orientation. Novel tasks without known solutions require the system to generate unique waypoint "fitness functions" while breaking down tasks. How might this work?
2. The number of high-scoring teams is small.
We're seeing increased competition activity. On Kaggle, there are 921 teams and 7,368 submissions.
However, there are available open source solutions that can reach a score of 26% out of the box and only 17 teams are achieving scores higher than this baseline. Only 4 teams have scored 30% or higher.
We remain hopeful that more contenders will make a submission before the 2024 competition ends. 2,183 Discord server members are sharing more about their approaches and progress each day, and we can only imagine the hard work going on behind the scenes.
3. ARC-AGI v1 is imperfect.
There are a number of aspects of ARC-AGI that could use improvement.
The private dataset is relatively small at only 100 tasks, opening up the risk of probing for information by making frequent submissions. We lowered the number of daily submissions to mitigate this, but ideally the private evaluation would not be open to this risk.
We can glean from the 2020 Kaggle contest data that over 50% of ARC-AGI tasks are brute forcible. Solving ARC-AGI tasks through brute force runs contrary to the goal of the benchmark and competition - to create a system that goes beyond memorization to efficiently adapt to novel challenges.
The public and private evaluation datasets have not been difficulty calibrated. We have evidence the private evaluation set is slightly harder. This results in score discrepancies between private and public evals and creates confusion for everyone when people make public claims about public eval scores assuming the private eval is similar.
Lastly, we have evidence some ARC tasks are empirically easy for AI, but hard for humans - the opposite of the intention of ARC task design.
Time for Action
To address these 3 challenges, we have a few updates today.
Grow the Prizes
We are excited to announce that we are increasing the Grand Prize from $500k to $600k!
The Grand Prize will be awarded to the top teams (up to 5) which score at least 85% during the active competition. Increasing the big prize raises the incentive for breakthrough approaches, which is the most important aspect of ARC Prize.
We're also increasing the 2024 Paper Award prizes from $50k to $75k, adding an additional prize for a 3rd place winner!
The new paper prizes will be awarded as follows:
- 1st place: $50k
- 2nd place: $20k
- 3rd place: $5k
The Paper Awards are designed to reward novel concepts that don't necessarily result in high-scoring submissions, but do move the field forward conceptually.
We hope these increased prizes encourage researchers to get their papers published and novel solutions submitted, which will raise the ambition of the community through an infusion of fresh ideas.
Ramp up Outreach
We're committing $75k to 2024 ARC Prize events designed to grow the number of competitive contestants and increase progress towards conceptual breakthroughs.
While we're proud of the reach and awareness the prize has gained, we've decided to be more proactive in recruiting potential participants. We're planning a university tour in October to visit more than a dozen US universities with top-tier AI programs on the east and west coasts.
We'll also be attending NeurIPS to share learnings and disseminate ideas through a paper detailing the 2024 competition and live talks at the "System 2 Reasoning At Scale" workshop.
We moved the announcement date for 2024 Prizes from December 3 to December 6, 2024 to better align with NeurIPS.
Details coming soon. Sign up to get notified.
Improve the Benchmark
Finally, we're committing $75k toward the creation of the next iteration of ARC-AGI.
Our goal is to make ARC-AGI even easier for humans and harder for AI. To do this, we plan to minimize brute forcibility, perform extensive human difficulty calibration to ensure that public and private datasets are well balanced, and significantly increase the dataset size.
Note: This initiative will not impact ARC Prize 2024.
Commitment to Open AGI
Now past the 3 month mark, we're leveling up our commitment to push open AGI forward.
If ARC Prize remains unbeaten through 2024, we are committed to doing the following:
- Keep increasing the prize pool.
- Keep running ARC Prize annually until an open solution is published.
- Keep improving ARG-AGI to make it the best AGI research target.
If the dream of realizing the benefits of open AGI in our lifetime resonates with you:
See you on the leaderboard.