
ARC-AGI-3 Preview: 30-day learnings
Highlighting the gap between humans and AI with Interactive Benchmarks

On July 17, we released a sneak peek of ARC-AGI-3, our first Interactive Reasoning Benchmark. These three preview games were our first contact with reality using a new format: video-game-like environments where agents and humans must perceive, plan, and act across multiple steps to achieve long-horizon goals.
Our goal was to gather data about human performance, learn how well AI systems perform on interactive tasks, and see how the community would engage with this new style of evaluation. To encourage further development, we hosted an ARC-AGI-3 Preview Agent competition.
30-Day takeaways:
-
Interactive benchmarks are easy (even fun) for humans, but hard for AI
Most humans beat the games, often enjoying them. Persistent test-takers "speed ran" to theoretical minimums. AI agents struggled to efficiently make progress. -
Some preview games were too friendly to random search
A few game designs could be brute-forced without reasoning. What we learn will help make future games more resistant to brute force and more reflective of intelligence. -
Action efficiency provides a clear intelligence signal
Measuring how efficiently environment information is converted into strategy reveals a clear divide between human-level and AI-level performance.
Why Interactive Reasoning Benchmarks
Traditionally, to measure intelligence, static benchmarks have been the yardstick. However, Interactive Reasoning Benchmarks (IRBs) test for a broader scope of capabilities:
- On-the-fly Learning - Like in ARC-AGI-1 & 2, the test-taker cannot simply memorize strategies to succeed at the games, it must recombine what it knows on the fly to make sense of novel situations.
- Exploration - Can the test-taker efficiently gather the information it needs from the environment via its own choices?
- Memory - Given previous experience, how does a test-taker choose to store that information for future use?
- Goal Acquisition - Can a test-taker set its own intermediate goals, even if the ultimate goal is unknown?
We released ARC-AGI-3 Preview to put these core design principles into action.
When compared to static benchmarks, instead of asking, "Can the test-taker recall the right answer?" interactive benchmarks ask, "Can they explore, learn, plan, and adapt when dropped into an entirely new environment?"
Interactive benchmarks also offer something static benchmarks cannot: action efficiency.
Instead of just checking whether a goal is reached, we can measure how many actions it takes to get there. In other words, we're tracking how efficiently a test taker converts information from the environment into a working strategy.
Inspired by Francois Chollet's On the Measure of Intelligence, this gives us a new way to define efficiency, and by extension, intelligence, as the conversion ratio between environment information and agent behavior.
This new metric is not a nice to have, it is foundational to measuring performance of frontier models and intelligence in general. Intelligence is efficiency.
ARC-AGI-3 Preview games
ARC-AGI-3 will be a set of hand-crafted novel, unique environments that are designed to test the skill-acquisition efficiency of artificial systems as compared to humans.
It will rely on previous ARC-AGI pillars (core priors, excluding reliance on language, trivia, or vast training data) to evaluate performance against human baselines.
The first three games released were meant to demonstrate a spectrum of game types. Some are agent based (moving around a single object on screen), while others are orchestration based (viewing and manipulating multiple objects at once).
Preview games released
| Game | Type | Description |
|---|---|---|
| ls20 | Agentic, map based | Navigate a map while bringing a matching symbol to another object. The symbol must go through various transformations in order for it to reach the goal. |
| ft09 | Non-agentic, logic | Match the pattern seen on the screen. Patterns occasionally overlap. |
| vc33 | Orchestration | Alternate volume of objects in order to match levels to pre-specified heights. |
| Private Game #1 | — | To be released |
| Private Game #2 | — | To be released |
| Private Game #3 | — | To be released |
The three private games used as a hidden holdout set for the ARC-AGI-3 Preview Agent Competition will be released in the coming weeks.
Human performance insights
Since the Preview launch, over 1,200 people have played more than 3,900 ARC-AGI-3 games.
To measure how efficiently humans play, we've adopted a scoring framework inspired by work from Josh Tenenbaum's lab, Human-Level Reinforcement Learning through Theory-Based Modeling, Exploration, and Planning.
The method is straightforward, track the number of actions taken to complete each level, then plot how that effort accumulates over time. This makes it easy to compare performance, not just between two humans, but more importantly, between humans and AI (more on this later).
We were also inspired by Shortest Path Length algorithms (such as Dijkstra's and A*) which focus on two questions:
- Did the agent complete its goal?
- How efficiently did it do it?
When this framework is used on ARC-AGI-3, we get a view of level progression vs action count. It may look like a simple chart, but it reveals a lot! Here's an example of human test data from, vc33, a public preview game.
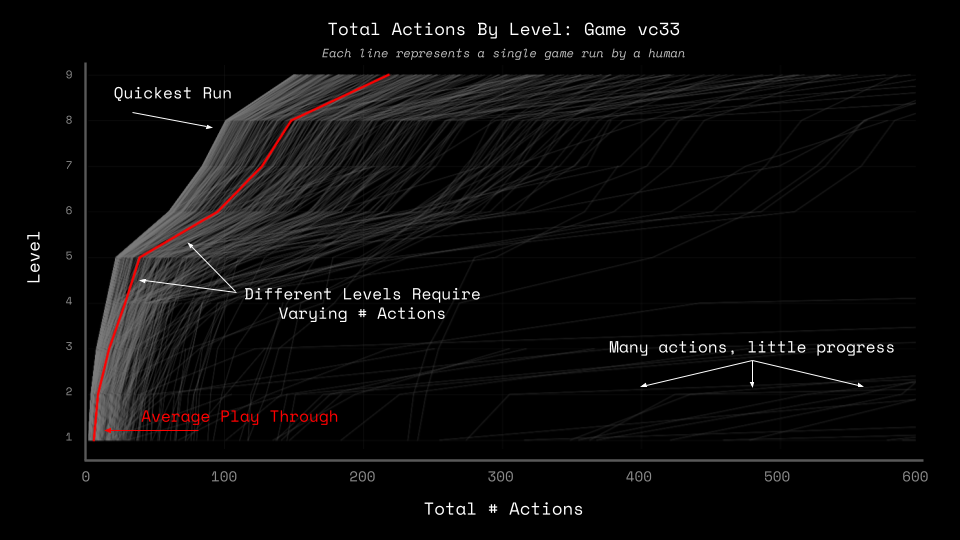
What we can learn from this chart:
- What is the least amount of action needed to complete a game? - After many practice runs, a persistent human is able to find the perfect path through a game per level. This path is the lowest number of actions needed to complete a game (the left-most line on the chart above)
- How quick is the average human? - Plotting the average # of actions across all human runs shows you the average number of actions taken per level
- The amount of action variance across levels - Different levels require different numbers of actions to be completed.
- The amount of action variance across games - Different games require different numbers of actions to be completed
Expanding this view to all 3 public games, we can start to see each game's unique characteristics.
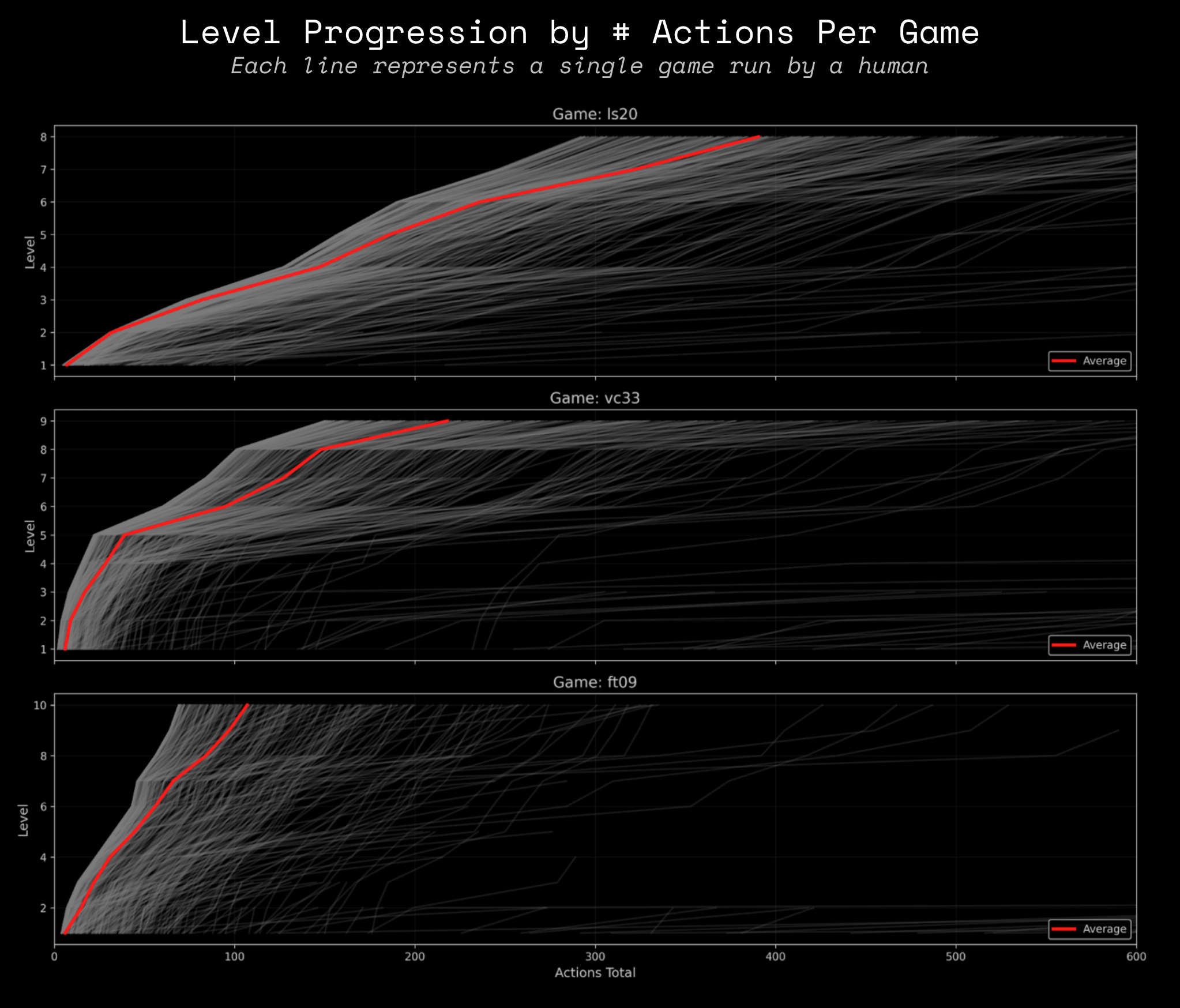
When measuring human performance, we only count a player's first run on a game to compare with AI's first run to measure learning efficiency, not memorization.
The dataset shown above comes from authenticated users. We can't guarantee that their first game run was truly their first time playing. Some may have played the game anonymously before logging in. So although this data is useful to understand action variability per level & game, it will not be used for standardized scoring.
For the production launch of ARC-AGI-3, we will rely on controlled human study of >200 participants to determine baselines.
Comparing humans to AI
Using this scoring framework, we can directly compare human and AI performance on a per-level basis by using action efficiency.
As a test-taker plays a game, they "spend" action in two ways:
- Exploration - Actions spent probing the environment to understand its rules
- Execution - Actions spent applying a strategy to reach the goal
Every player, human or AI, must use exploratory actions before executing a strategy. Humans are generally good at this: they explore briefly, then execute successfully. Random brute-force agents, however, may eventually complete a level but require far more actions. They aren't effective at turning information from the environment into a workable strategy.
To understand how well AI is doing relative to humans, we can see how many actions it takes an agent to complete a level as a percent of how many actions it takes a human to do the same.
This sets the stage for our scoring framework:
Score agents by their per-level action efficiency (as compared to humans), normalized per game, across all games.
Broken down:
- “Score agents by their per-level action efficiency” - For each level that a test-taker completes, evaluate how many actions it took to complete.
- “As compared to human baseline” - For each level that is scored, compare the test-takers score to the human baseline that was observed during human testing.
- “Normalized per game” - Each level will be scored in isolation. Each individual game will get a score between 0%-100%. Similar to ARC-AGI 1 & 2 tasks.
- “Across all games” - Total score will be the sum of individual game scores divided by the total number of games. Output will be a score between 0%-100%.
Agent Preview competition
Alongside the launch of the first ARC-AGI-3 Preview games, we launched an Agent Preview Competition with the goal of incentivizing the collective intelligence of the community to build. By putting ARC-AGI-3 Preview into the hands of developers, we could test our game and API design early before scaling up development for the full benchmark.
In partnership with Hugging Face, who generously sponsored the competition, we released the first version of our API. Developers could train and test their agents on the public set.
Our aim was to discourage overfitting and reward generalization. The competition would be judged based off the agent's performance on 3 additional private games.
The competition ran for 30 days, open to anyone worldwide. In the end, we received 12 submissions, with 8 tested against the private games. Scores were computed using prelimary results from human testing in the scoring framework above.
Winners of the ARC-AGI-3 Preview Competition
1st Place: StochasticGoose @ Tufa Labs: Score: 12.58%, Levels Completed: 18
Convolutional Neural Network Action-learning agent. It uses a simple reinforcement learning approach to predict which actions will cause frame changes, enabling more efficient exploration than random selection. Lead Developer: Dries Smit, Adviser/Reviewer: Jack Cole. Blog Recap:

In the beginning the agent uses nearly 350 moves clicking actions with no result. Then it "learns" what is clickable and starts exploiting the action space.
2nd Place: Blind Squirrel: Score: 6.71%, Levels Completed: 13
Explore-and-learn agent that builds a state graph from frames. It prunes actions that create loops or don't change state. Whenever the score improves, it back-labels that level with distances and retrains a small ResNet18-based value model to rank (state, action) pairs toward the next milestone, then repeats until win or cap. Developer: Will Dick. Blog Recap

Honorable Mentions
- Dhana Abhiraj - Play Zero Agent (Blog Recap)
- Evgenii Rudakov - Explore It Till You Solve It (Paper Recap)
- Ujjwal Chadha, Maya Nguyen, Shobhit Singhal, Filip Dominas - Fluxonian
Top Submissions
| Agent | Team | Type | Score | Games Completed | Levels Completed | Actions | Replays |
|---|---|---|---|---|---|---|---|
| StochasticGoose | Dries Smit - Lead Developer Jack Cole - Advisor Review | Smart Random (CNN) | 12.58% | 2 | 18 | 255,964 | ft09 ls20 vc33 |
| Blind Squirrel | Will Dick | Smart Random (Rules) | 6.71% | 1 | 13 | 109,108 | ft09 ls20 vc33 |
| Explore It Till You Solve It | Evgenii Rudakov (Developer) | Smart Random (Frame Graph) | 3.64% | 0 | 12 | 278,158 | ft09 ls20 vc33 |
| GuidedRandomAgent | Bob | Smart Random (Rules) | 2.24% | 1 | 11 | 39,881 | ft09 ls20 vc33 |
| Fluxonian | Ujjwal Chadha (Engineer) Maya Nguyen (Engineer) Shobhit Singhal (Engineer) Filip Dominas (TPM) | DSL + LLM | 8.04% | 0 | 5 | 11,890 | ft09 ls20 vc33 |
| Play Zero Agent | Dhana Abhiraj (Developer) | Random + LLM Video | 4.37% | 0 | 5 | 7,226 | ft09 ls20 vc33 |
| Tomas Engine | Cristian Valdivia (Developer) - Blog Post Recap | LLM - Limited Results, Crashed Often | 3.70% | 0 | 1 | 79 | ft09 ls20 vc33 |
Notes:
- For agents that required large (>10K) actions, the replays files have been truncated for viewing.
- View the winners page and archived competition page.
Learnings moving forward
Based on preview feedback, we're shipping several practical improvements today, and more later with the full benchmark release:
- Action undo - Players wanted a simple way to step back. We'll add an undo button to both the API and UI. Not all games will support this.
- Clearer guidance on which actions are available per game - Too many users were unsure which actions were valid. We'll explicitly show available actions, and specifically call out when grid-clicking is allowed.
- Clear docs reduce friction - Switching to Mintlify docs mid-competition worked well. Most users signed up, ran the sample random agent immediately, and got started quickly.
- Local execution preferred - While the hosted API made onboarding easy, many requested local/offline execution for training at scale. We're exploring an offline engine to support this.
- Early exit mechanism - Some replays ballooned to tens of gigabytes due to brute-force action loops. We'll add caps and early exits to keep files manageable.
- More precise scoring vocabulary - We'll distinguish between games completed, levels completed, and score. "Score" will be reserved for normalized performance against human baselines.
Time to build
The ARC-AGI-3 competition is wrapped but the preview is still live!
Three games are now available on three.arcprize.org, and we encourage you to keep building.
There are plenty of ways to get involved with ARC-AGI-3:
- Submit new game ideas - We're actively building the next wave of environments.
- Share your agents - We'll be highlighting creative solutions from the community over the next six months.
- Research - The current API has rate caps, but if you need more for research, reach out to team@arcprize.org. We're also exploring an offline engine and welcome feedback on how best to design it.
Play, build, train, and help us create the future of machine intelligence benchmarking.