
The Hidden Drivers of HRM's Performance on ARC-AGI
We scored on hidden tasks, ran ablations, and found that performance comes from an unexpected source
On June 8, 2025, the Hierarchical Reasoning Model (HRM) paper was published by Guan Wang et al. The release went viral within the AI community. X/Twitter discussions hit over 4 million views and tens of thousands of likes [1, 2, 3, 4] and YouTube videos dissecting the work surpassed 475K views [1, 2, 3, 4].
The headline claim of the paper: the brain-inspired architecture of HRM scored 41% on ARC-AGI-1 with only 1,000 training tasks and a 27M (relatively small) parameter model.
Due to the popularity and novelty of the approach, we set out to verify HRM performance against the ARC-AGI-1 Semi-Private dataset - a hidden, hold-out set of ARC tasks used to verify that solutions are not overfit. We decided to go deeper than our typical score verification to further understand what aspects of HRM lead to better model performance.
Summary of our findings:
First of all: we were able to approximately reproduce the claimed numbers. HRM shows impressive performance for its size on the ARC-AGI Semi-Private sets:
- ARC-AGI-1: 32% - Though not state of the art, this is impressive for such a small model.
- ARC-AGI-2: 2% - While scores >0% show some signal, we do not consider this material progress on ARC-AGI-2.
At the same time, by running a series of ablation analyses, we made some surprising findings that call into question the prevailing narrative around HRM:
- The "hierarchical" architecture had minimal performance impact when compared to a similarly sized transformer.
- However, the relatively under-documented "outer loop" refinement process drove substantial performance, especially at training time.
- Cross-task transfer learning has limited benefits; most of the performance comes from memorizing solutions to the specific tasks used at evaluation time.
- Pre-training task augmentation is critical, though only 300 augmentations are needed (not 1K augmentations as reported in the paper). Inference-time task augmentation had limited impact.
Findings 2 & 3 suggest that the paper's approach is fundamentally similar to Liao and Gu's "ARC-AGI without pretraining".
Want to skip to the technical findings? See Analyzing HRM's Contribution to ARC Scores.
Hierarchical Reasoning Model
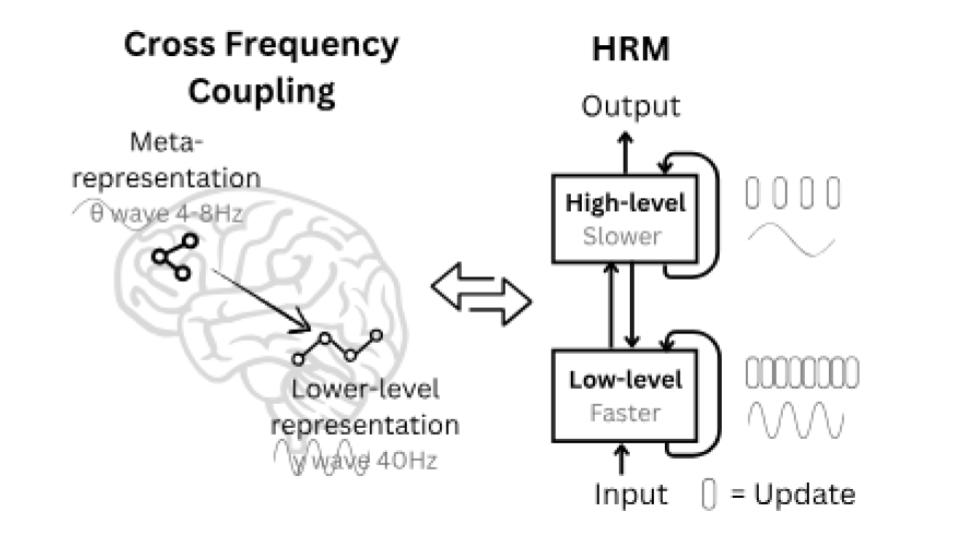
The Hierarchical Reasoning Model, published by Sapient, a Singapore-based AI research lab, is said to be inspired by the hierarchical and multi-time scale processing of the human brain.
HRM is a 27M parameter model that uses iterative refinement over a few short "thinking" bursts.
Each burst produces:
- A predicted output grid - This is the model's work-in-progress prediction to an ARC-AGI task.
- A "halt or continue" score - This score determines whether or not to continue refining the prediction or submit it as final.
If the model chooses to continue refining, the work-in-progress prediction is run through another "thinking" burst. This is the outer loop: prediction, ask "am I done?", either stop or refine.
Within the outer loop, HRM runs two coupled, recurrent modules "H" (slow planner) and "L" (fast worker). These two modules work together to update a shared hidden state rather separate outputs. The net effect is that the model alternates between plan (H) and details (L) until the internal state "agrees with itself" enough to produce an answer.
The model uses a learned "halt" signal which is an adaptive compute mechanism to control the number of refinements made.
A key piece of this process is task augmentation. This is the process of applying transformations (object rotations, flips, etc.) to each task in order to tease out the underlying task rules rather than overfit on specific shapes or colors.
At test time, the model runs the same augmentations to make predictions. Those predictions are "de-augmented" (to return to the original task format) and then simple majority voting determines which will be the final prediction.
Predictions are made over an embedding space via transduction (direct output from deep learning) rather than induction (produces a program which applies the transformation). For more on transduction vs induction in ARC-AGI, see the winning 2024 ARC Prize paper Combining Induction And Transduction For Abstract Reasoning by Wen-Ding Li et al.
ARC-AGI Verification Process
The ARC-AGI benchmark has 3 primary datasets for testing:
- Public Training Set - Public data that is an introduction to the ARC-AGI data format. Researchers train and iterate models on this data.
- Public Evaluation Set - Public data intended for researchers to self-evaluate the performance of their models after training.
- Semi-Private Evaluation Set - A hold-out set that is used to verify claims on ARC-AGI. This dataset is not available online to train on, adding to the confidence that it provides a clean signal of model performance. It's called "semi-private" because verifying third-party services (like models from OpenAI, xAI, etc.) means we can't ensure the data will remain fully private forever, and it's intended to be replaced eventually.
In addition to these dataset types, ARC-AGI currently has 2 released versions:
- ARC-AGI-1 - 2019, designed to challenge deep learning systems
- ARC-AGI-2 - 2025, designed to challenge reasoning systems
We test selected bespoke solutions, like HRM, in accordance with our testing policy. To be considered for verification, solutions must be open source, cost less than $10K to run, and complete in under 12 hours.
Official Verified HRM ARC-AGI Scores
ARC-AGI-1 (100 Tasks)
Score: 32%, Runtime: 9h 16m, Total Cost: $148.50 ($1.48/task)
32% on ARC-AGI-1 is an impressive score with such a small model. A small drop from HRM's claimed Public Evaluation score (41%) to Semi-Private is expected. ARC-AGI-1's Public and Semi-Private sets have not been difficulty calibrated. The observed drop (-9pp) is on the high side of normal variation. If the model had been overfit to the Public set, Semi-Private performance could have collapsed (e.g., ~10% or less). This was not observed.
This result shows that, indeed, something interesting is going on with HRM.
Note: The relatively high cost of running HRM is due to training and inference coupled in a single run. The paper's authors have mentioned they are working to decouple this process in order to submit their solution to the ARC Prize 2025 Kaggle competition.
ARC-AGI-2 (120 Tasks)
Score: 2%, Runtime: 12h 35m, Total Cost: $201 ($1.68/task)
ARC-AGI-2 is significantly harder than ARC-AGI-1, so a large performance drop is expected. Unlike ARC-AGI-1, the ARC-AGI-2 Public and Semi-Private sets are difficulty-calibrated. Scores on each should, in principle, be similar. Though >0% shows model strength, we do not consider 2% as meaningful progress on ARC-AGI-2.
Note: We opted to include 10 optional checkpoints (~5 minutes each), adding ~50 minutes in total. While the HRM submission exceeded the 12-hour run limit, we still consider it valid.
Analyzing HRM's Contribution to ARC Scores
The question we were most curious to answer during deeper analysis was: "what is the key component of the HRM architecture that contributes the most towards success on ARC-AGI?"
We looked closer at the 4 main components of the HRM paper: the HRM model architecture, the H-L hierarchical computation, the outer refinement loop, and the use of data augmentation. Ndea researcher Konstantin Schürholt drove this analysis.
We tested:
- "Hierarchical" H and L loop performance contributions
- What performance does HRM provide over a base transformer?
- What impact does varying the hierarchical compute have?
- Varying the max "halt or continue" loops
- How well does the ACT grader do compared to a fixed number of loops (with no decision to halt refinements)?
- Impact of cross-task transfer learning
- What is the impact of the inclusion of the training set tasks and the ConceptARC tasks at training time, compared to only training on the evaluation tasks?
- Augmentation count
- Varying the number of augmentations that were created from each task.
- Model/training variations (size and duration)
Finding #1: The "hierarchical" architecture had minimal performance impact when compared to a similarly sized transformer.
The paper proposes that the HRM architecture is the key to realize hierarchical reasoning - combining slower-paced guidance (H-level) with faster-paced thinking (L-level).
To understand the impact of this architecture, we performed 2 experiments:
- Vary the amount of iterations in the hierarchical components.
- Replace the HRM model with a similar sized transformer.
For easy comparability, the transformer has the same number of parameters as the HRM model (~27M). In all experiments, we keep all other components of the HRM pipeline constant.
Comparing HRM with a regular transformer shows 2 interesting results, see Figure 3.
First, a regular transformer comes within ~5pp of the HRM model without any hyperparameter optimization. The gap is smallest for just 1 outer loop, where both models are on par performance-wise.
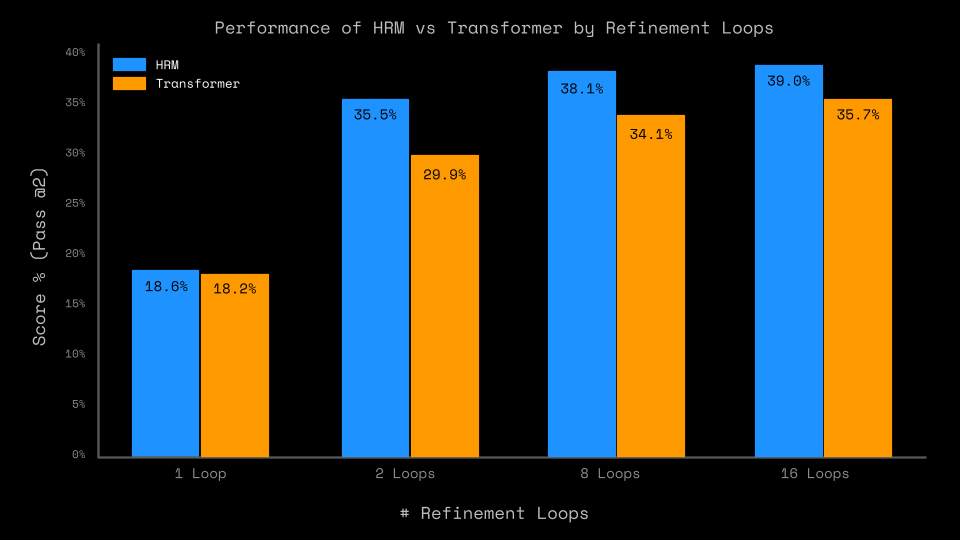
For more than 1 outer loop, HRM performs better, although the gap closes for higher numbers of outer loops. Please note that although matched in parameter count, HRM uses more compute, which may explain parts of the difference. The benefit of increasing compute may yield diminishing returns with more outer loops, which would match with our results.
We further varied the number of H-level and L-level steps to analyze their impact. We found that increasing or decreasing the number of iterations from the baseline (L=2 and H=2) led to worse performance.
These results suggest that the performance on ARC-AGI is not an effect of the HRM architecture. While it does provide a small benefit, a replacement baseline transformer in the HRM training pipeline achieves comparable performance.
Finding #2: The under-documented "outer loop" refinement process drove substantial performance gains.
In addition to the hierarchical architecture, the HRM paper proposes to use an outer loop ("recurrent connectivity") around the model. This feeds the model output back into itself, allowing the model to iteratively refine its predictions.
In addition, it uses "adaptive computational time" (ACT), to control the amount of iterations it has to spend on a specific task. The ACT decides whether or not to halt the prediction or to continue refining.
This part of the HRM method is similar to the Universal Transformer, which features both a recurrent refinement loop around a transformer model, as well as a version of ACT.
In our second series of experiments, we wanted to understand what impact the outer refinement loop, as well as ACT, have on the overall performance. We varied the number of maximum outer loops during training while using maximum loops during inference (following the HRM implementation).
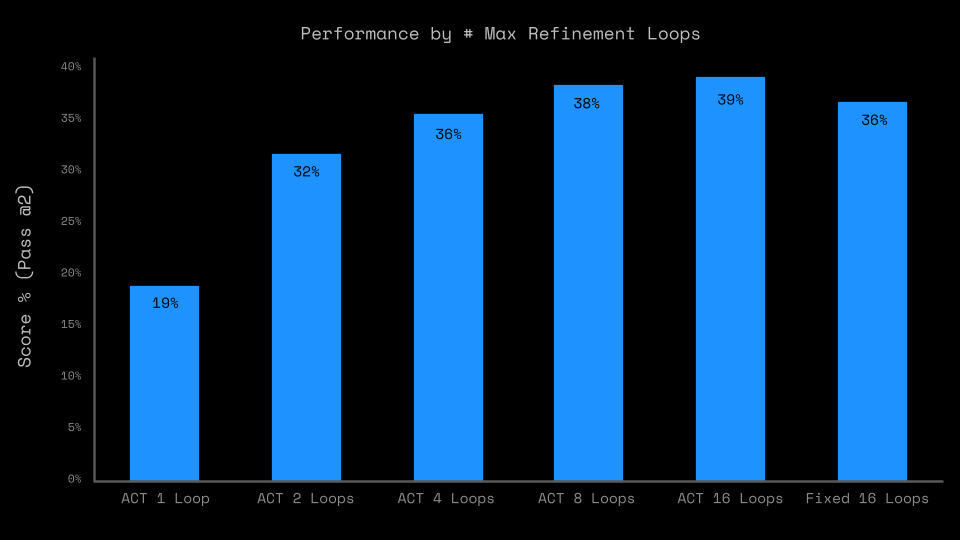
Iterating over data by refining it has a strong impact, as the jump from 1 (no refinement) to 2 (1 refinement) shows.
As Figure 4 shows, the number of outer loops has a significant impact on model performance - from no refinement (1 loop) to just 1 refinement, performance jumps by +13pp. From 1 to 8 refinement loops, the Public Evaluation set performance doubles.
A secondary finding is that utilizing ACT during training does indeed lead to reduced actual refinement steps per task. However, while using ACT does improve performance, the difference is within a few percentage points when compared to a fixed 16-loop run.
The results indicate that the refinement outer loop is an essential driver for HRM's performance.
To understand the impact of refinement during training vs. inference, we further varied the number of inference refinement loops independently from the training refinement loops.
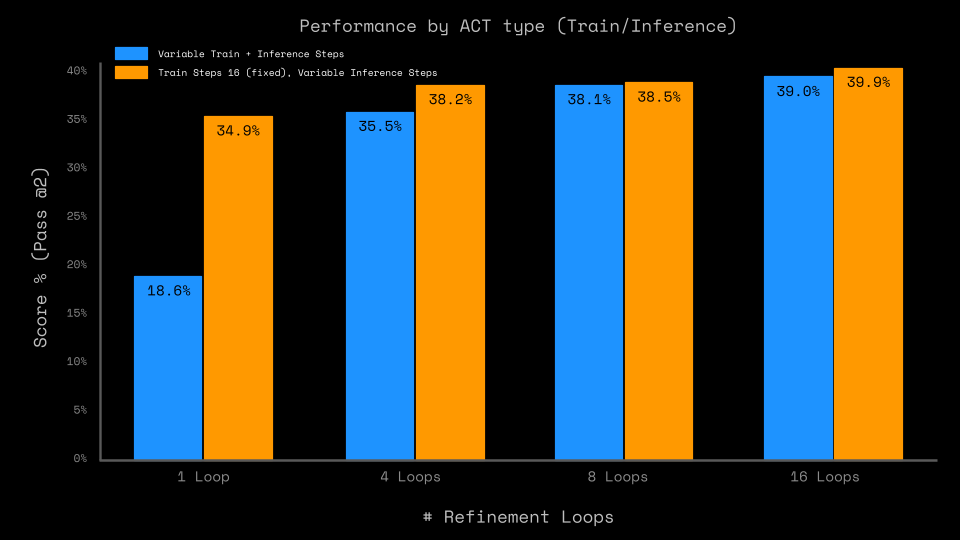
To that end, we compare two setups. In the first, we use the same number of refinement loops for training and inference. For the second, we train a model with a maximum of 16 refinement loop steps and evaluate it with 1, 4, 8, and 16 refinement steps.
Comparing these two classes of models shows a material difference, particularly at low-inference refinement steps (1 and 4), see Figure 5. Training with more refinement improves the performance of predictions with a single refinement loop by >15pp, even though one loop means a single forward pass without any refinement. Further refinement loops at inference don't have as big of an impact. This indicates that training with refinement loops is more important than using the refinement for inference.
Finding #3: The impact of cross-task transfer learning is limited.
In the original paper, HRM is trained on augmented versions of the demonstration pairs of 960 tasks:
- The 400 tasks from the ARC-AGI-1 training set.
- 160 tasks from the closely-related ConceptARC benchmark.
- The 400 tasks from the ARC-AGI-1 evaluation set, which are the tasks being targeted during evaluation.
To note, this does not imply any data leakage, since the model never sees at training time the test pairs of the evaluation tasks -- which is what the model gets evaluated on.
We wanted to understand the impact of cross-task transfer learning compared to the impact of inferring and memorizing solutions for the specific tasks used during evaluation. We ran the following experiment: we trained on only the 400 evaluation tasks -- cutting out the 400 tasks from the training set and the 160 tasks from the ConceptARC dataset.
With this setup, the model reached 31% pass@2 accuracy, a relatively small drop from the original 41%. This suggests that the large majority of the performance is driven by training on the tasks seen at evaluation time. This means that what HRM does is fundamentally a zero-pretraining test-time training approach, similar to Liao and Gu's "ARC-AGI without pretraining". This amounts to using the model as a kind of program synthesis substrate -- using gradient descent on the demonstration pairs of a task to encode in the weights of the model a program that performs the task.
To note, in our experiment, there is still some amount of cross-task transfer learning happening -- between different tasks in the evaluation set. A stronger version of our experiment would be to run the HRM pipeline individually on each evaluation task, so that the model would only see at training time augmentations of the demonstration pairs of the one task it gets evaluated on. This would bring the HRM setup to parity with Liao and Gu's setup. We did not have time to run this experiment, but we speculate that the results would closely match Liao and Gu's (21% pass@2).
Finding #4: Pre-training task augmentation is critical.
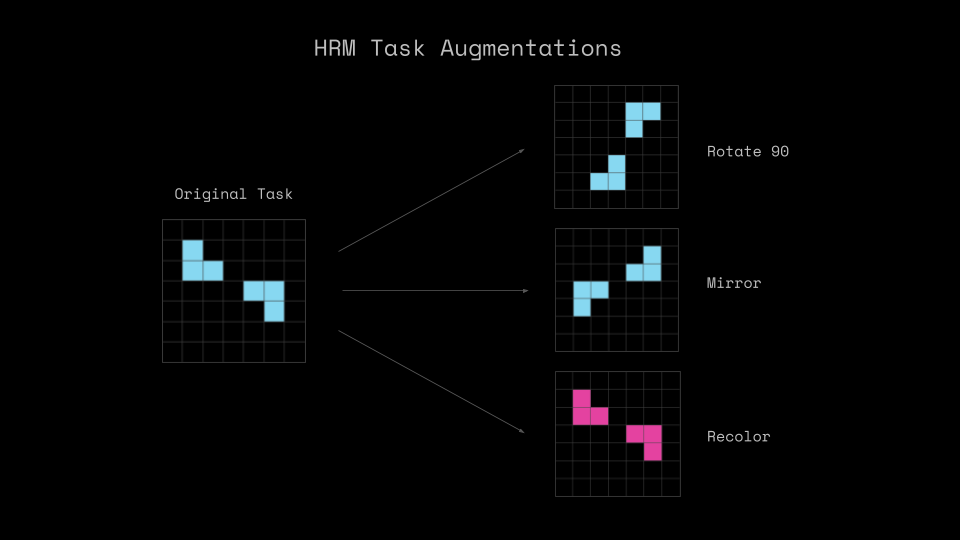
Another important component of the HRM pipeline we investigated were the task augmentations.
Augmenting data is a common method in deep learning to increase the number of samples in the dataset and improve model generalization. This means applying rotations, flips, or colors swaps to a task which produces new data without changing the underlying concept of the task.
HRM makes predictions for all augmented versions of a task and then reverts (or "de-augments") augmented predictions so they are in the original task format. The model then does a majority vote on the predictions to select the final candidate.
We tested the following modifications to the baseline HRM:
- The number of maximum augmentations when compiling the dataset
- The number of maximum predictions used for the majority vote
Because HRM can only process augmentation types it encountered during training, our inference-time variation in #2 is limited to reducing the number of augmentations, not increasing it.
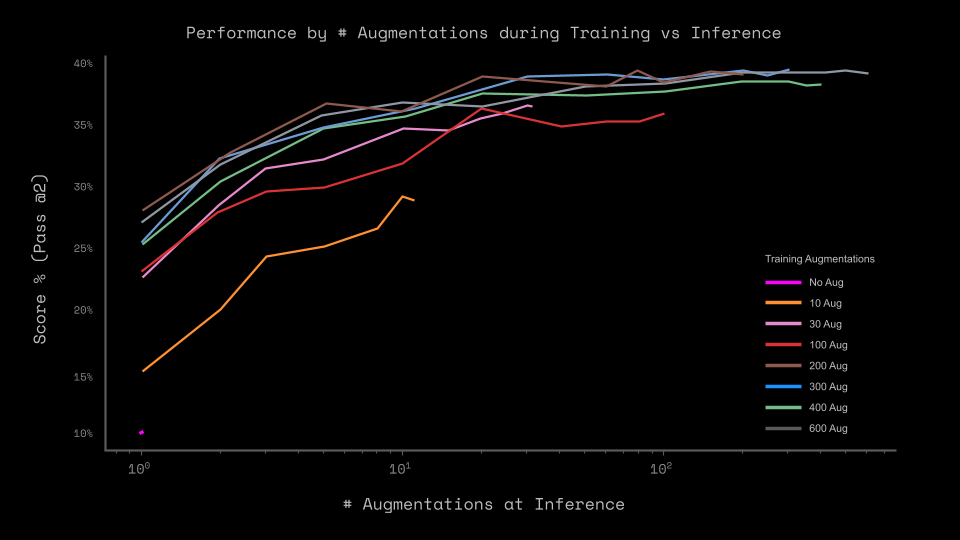
The right end of a line marks the point where the number of training and inference augmentations are equal.
The results in Figure 7 show 2 trends. First, using data augmentations does improve performance significantly. However, only using 300 augmentations, instead of the 1,000 as the paper used, achieves near max performance. Using only 30 augmentations (3% of total used in paper) comes within 4% of max performance.
Second, using data augmentations during training appears more important than to get a bigger pool for majority voting. The performance drop for models trained with more augmentations is significantly lower when they perform inference with a smaller pool.
Other Technical Learnings
Looking under the hood of HRM led to a few other interesting findings.
First and most importantly, HRM breaks up ARC-AGI tasks into individual input-output pairs, which they call puzzles. Each puzzle receives a puzzle_id, which consists of the task hash and a code for the augmentation that has been applied to this particular puzzle.
At training and inference time, the model only receives the input and the puzzle_id - there is no few-shot context with other input-output examples of the task. The HRM model has to learn to relate a puzzle_id to a specific transformation, so that it can predict the output from the input.
To that end, it feeds the puzzle_id into a large embedding layer. This embedding layer is key - without it, the model would not know what to do with an input. This presents a major limitation: the model can only be applied on puzzles with puzzle_ids it has seen at training time.
In conversation with the authors on that topic, they explained that changing the puzzle embedding for few-shot contexts presents a complex engineering challenge. In earlier versions, they had done the comparison and found that few-shot contexts work well on larger ARC-like datasets, but puzzle embeddings perform significantly better on the sample-constrained ARC. We did not replicate these experiments, but this suggests interesting future work.
For the same reason, in this version of HRM, the inference data has to be part of the training dataset. Varying, for example, the number of augmentations separately is not straight forward.
Lastly, while the refinement loop clearly has a significant impact on performance, HRM is purely transductive. While it is possible to roll out the refinement steps, the underlying program remains implicit. Our hypothesis is this will not generalize.
Open Questions & Future Work
Our experiments with HRM have brought some clarity to what makes HRM perform well on ARC-AGI, but other questions remain. In addition to the ones mentioned above, here are more we invite the community to explore.
- What impact does the
puzzle_idembedding have on model performance? How does it compare to providing the remaining examples in the tasks as context? - How much does HRM generalize beyond its training data? Is there any way to fine-tune HRM on new data?
- What is the impact of the learned halting mechanism at inference time? Are benefits limited to saving compute, or can they also improve performance?
- Does the refinement idea generalize to other approaches, like inductive methods that synthesize explicit programs?
- What performance could be achieved by training and evaluating individually on each evaluation task? (Eliminating all cross-task transfer learning.)
- Which specific augmentation types lead to higher performance? Rotations? Color Swaps? Why?
Reproducibility & Resources
To reproduce our experiments and continue the research, we've published our code. It builds on the official HRM code and adds small modifications. The repository contains instructions of how to set up the environment, change parameters, and run the experiments.
Thanks to the paper authors for sharing their results and for their responsiveness in discussing their work. Thanks to researcher Konstantin Schürholt of Ndea for leading this analysis.
Let us know what you thought of this style of in-depth technical analysis. Our mission is to drive open AGI progress, and we're excited to continue to highlight novel approaches through ARC Prize 2025 and our original content.
This post is also available via slide deck.