
OpenAI o1 Results on ARC-AGI-Pub
ARC Prize testing and notes on OpenAI's new o1 model
UPDATE: the full version of o1 was released December 5, 2024, important updates here.
Over the past 24 hours, we got access to OpenAI's newly released o1-preview and o1-mini models specially trained to emulate reasoning. These models are given extra time to generate and refine reasoning tokens before giving a final answer.
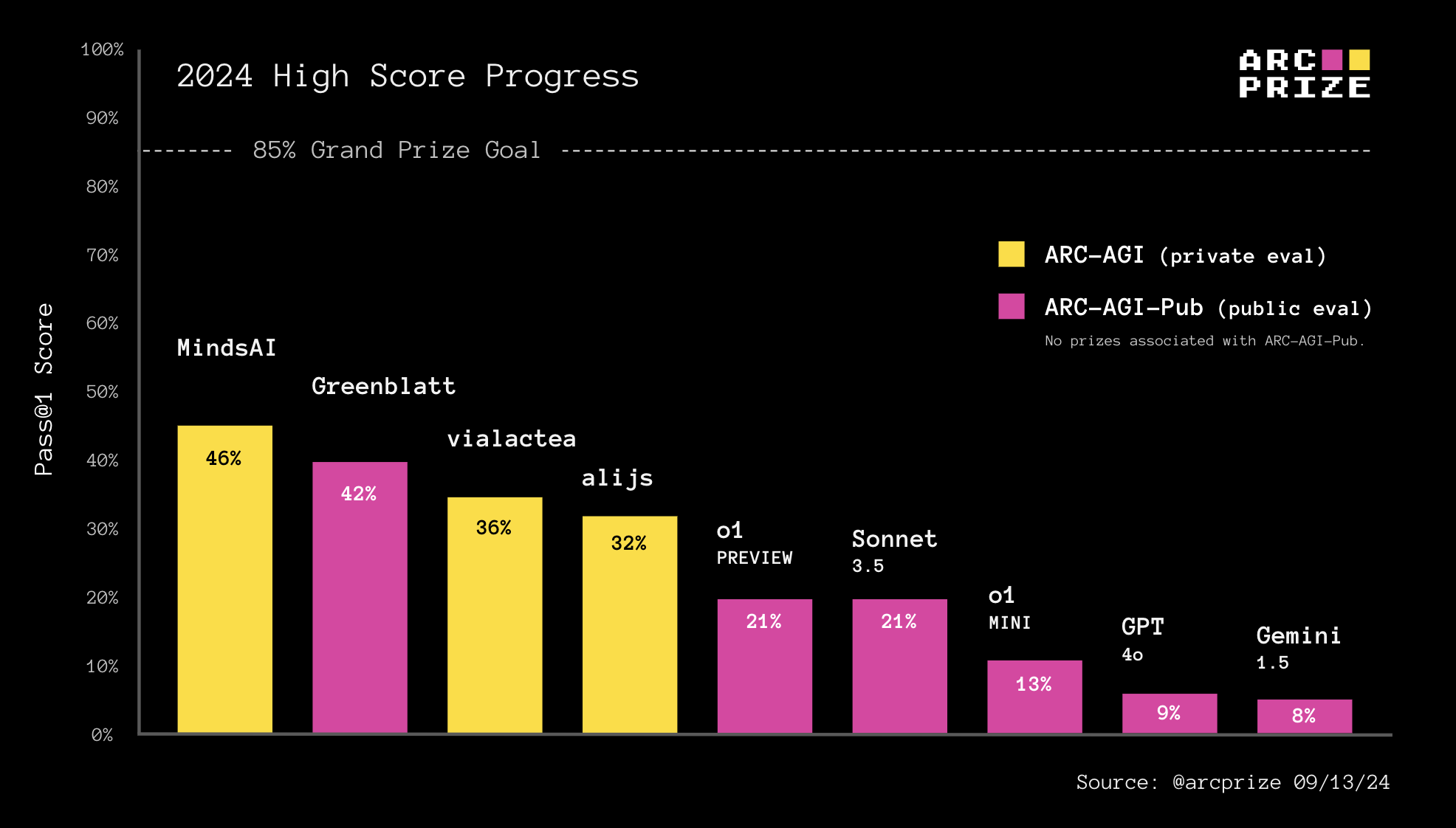
Hundreds of people have asked how o1 stacks up on ARC Prize. So we put it to test using the same baseline testing harness we've used to assess Claude 3.5 Sonnet, GPT-4o, and Gemini 1.5. Here are the results:
Is o1 a new paradigm towards AGI? Will it scale up? What explains the massive difference between o1's performance on IOI, AIME, and many other impressive benchmark scores compared to only modest scores on ARC-AGI?
There's a lot to talk about.
Chain-of-Thought
o1 fully realizes the "let's think step by step" chain-of-thought (CoT) paradigm by applying it at both training time and test time inference.
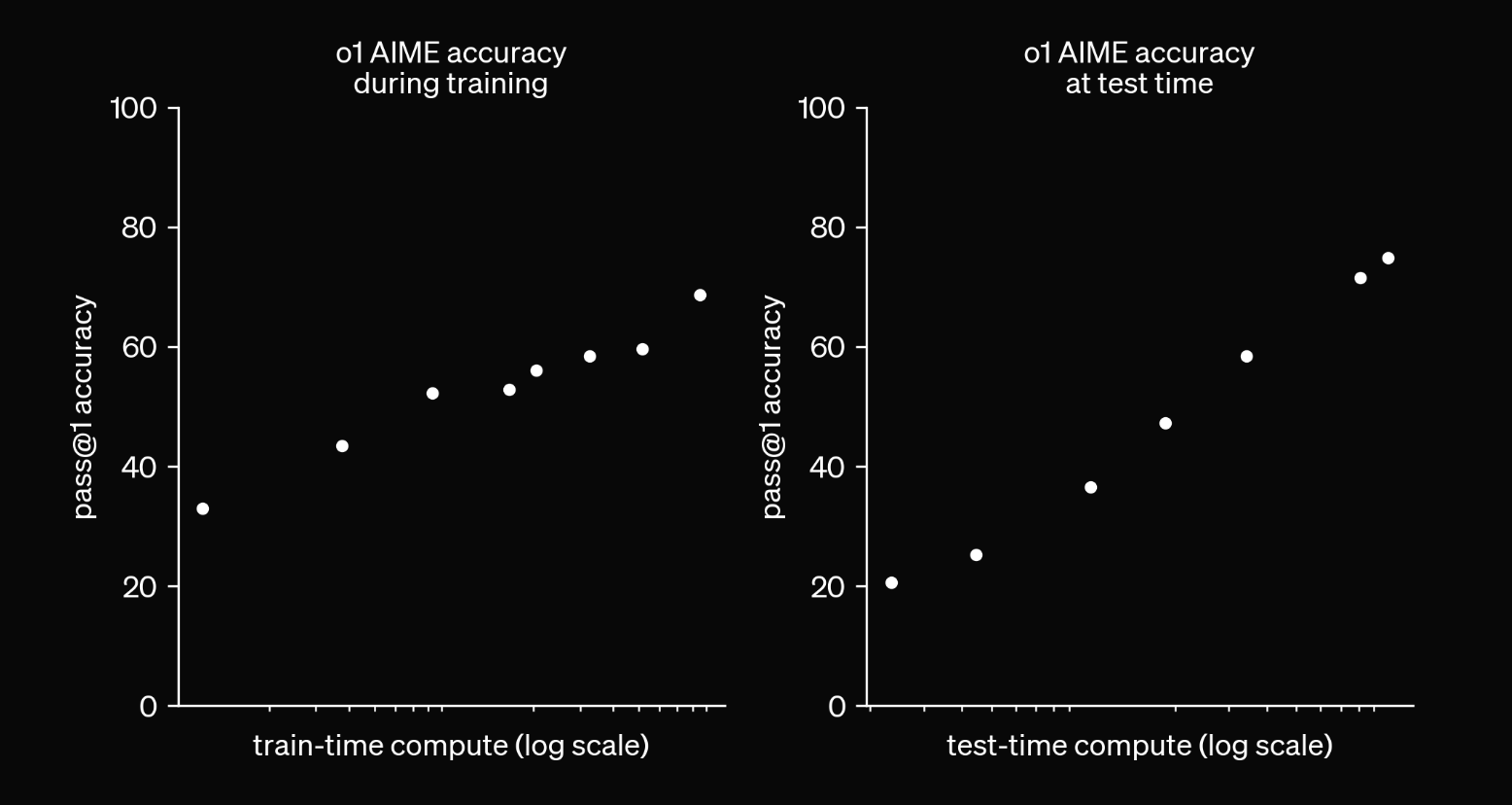
In practice, o1 is significantly less likely to make mistakes when performing tasks where the sequence of intermediate steps is well-represented in the synthetic CoT training data.
At training time, OpenAI says they've built a new reinforcement learning (RL) algorithm and a highly data-efficient process that leverages CoT.
The implication is that the foundational source of o1 training is still a fixed set of pre-training data. But OpenAI is also able to generate tons of synthetic CoTs that emulate human reasoning to further train the model via RL. An unanswered question is how OpenAI selects which generated CoTs to train on?
While we have few details, reward signals for RL were likely achieved using verification (over formal domains like math and code) and human labeling (over informal domains like task breakdown and planning.)
At inference time, OpenAI says they're using RL to enable o1 to hone its CoT and refine the strategies it uses. We can speculate the reward signal here is some kind of actor + critic system similar to ones OpenAI previously published. And that they're applying search or backtracking over the generated reasoning tokens at inference time.
Test-Time Compute
The most important aspect of o1 is that it shows a working example of applying CoT reasoning search to informal language as opposed to formal languages like math, code, or Lean.
While added train-time scaling using CoT is notable, the big new story is test-time scaling.
We believe iterated CoT genuinely unlocks greater generalization. Automatic iterative re-prompting enables the model to better adapt to novelty, in a way similar to test-time fine-tuning leveraged by the MindsAI team.
If we only do a single inference, we are limited to reapplying memorized programs. But by generating intermediate output CoTs, or programs, for each task, we unlock the ability to compose learned program components, achieving adaptation. This technique is one way to surmount the #1 issue of large language model generalization: the ability to adapt to novelty. Though like test-time fine-tuning it does ultimately remain limited.
When AI systems are allowed a variable amount of test-time compute (e.g., the amount of reasoning tokens or the time to search), there is no objective way to report a single benchmark score because it's relative to the allowed compute. That is what this chart shows.
More compute means more accuracy.
When OpenAI released o1 they could have allowed developers to specify the amount of compute or time allowed to refine CoT at test-time. Instead, they've "hard coded" a point along the test-time compute continuum and hid that implementation detail from developers.
With varying test-time compute, we can no longer just compare the output between two different AI systems to assess relative intelligence. We need to also compare the compute efficiency.
While OpenAI's announcement did not share efficiency numbers, it's exciting we're now entering a period where efficiency will be a focus. Efficiency is critical to the definition of AGI and this is why ARC Prize enforces an efficiency limit on winning solutions.
Our prediction: expect to see way more benchmark charts comparing accuracy vs test-time compute going forward.
ARC-AGI-Pub Model Baselines
OpenAI o1-preview and o1-mini both outperform GPT-4o on the ARC-AGI public evaluation dataset. o1-preview is about on par with Anthropic's Claude 3.5 Sonnet in terms of accuracy but takes about 10X longer to achieve similar results to Sonnet.
| Name | Score (public eval) | Verification Score (semi-private eval) | Avg Time/Task (mins) |
|---|---|---|---|
| o1-preview | 21.2% | 18% | 4.2 |
| Claude 3.5 | 21% | 14% | 0.3 |
| o1-mini | 12.8% | 9.5% | 3.0 |
| GPT-4o | 9% | 5% | 0.3 |
| Gemini 1.5 | 8% | 4.5% | 1.1 |
To get the baseline model scores on the ARC-AGI-Pub leaderboard, we're using the same baseline prompt we used to test GPT-4o. When we test and report results on pure models like o1, our intention is to get a measurement of base model performance, as much as that is possible, without layering on any optimization.
Others may discover better ways to prompt CoT-style models in the future, and we are happy to add those to the leaderboard if verified.
o1's performance increase did come with a time cost. It took 70 hours on the 400 public tasks compared to only 30 minutes for GPT-4o and Claude 3.5 Sonnet.
You can use our open source Kaggle notebook as a baseline testing harness or starting point for your own approach. The SOTA submission on the public leaderboard is the result of clever techniques in addition to cutting edge models.
Maybe you can figure out how to leverage o1 as a foundational component to achieve a higher score in a similar way!
Is AGI Here?
On this chart, OpenAI shows a log-linear relationship between accuracy and test-time compute on AIME. In other words, with exponentially increasing compute, accuracy goes up linearly.
A new question many are asking: how far does this scale?
The only conceptual limit to the approach is the decidability of the problem posed to the AI. So long as the search process has an external verifier which does contain the answer, you will see accuracy scale up logarithmically with compute.
In fact, the reported results are extremely similar to one of ARC Prize's top approaches by Ryan Greenblatt. He achieved a score of 43% by having GPT-4o generate k=2,048 solution programs per task and deterministically verifying them against the task demonstrations.
Then he assessed how accuracy varied for different values of k.
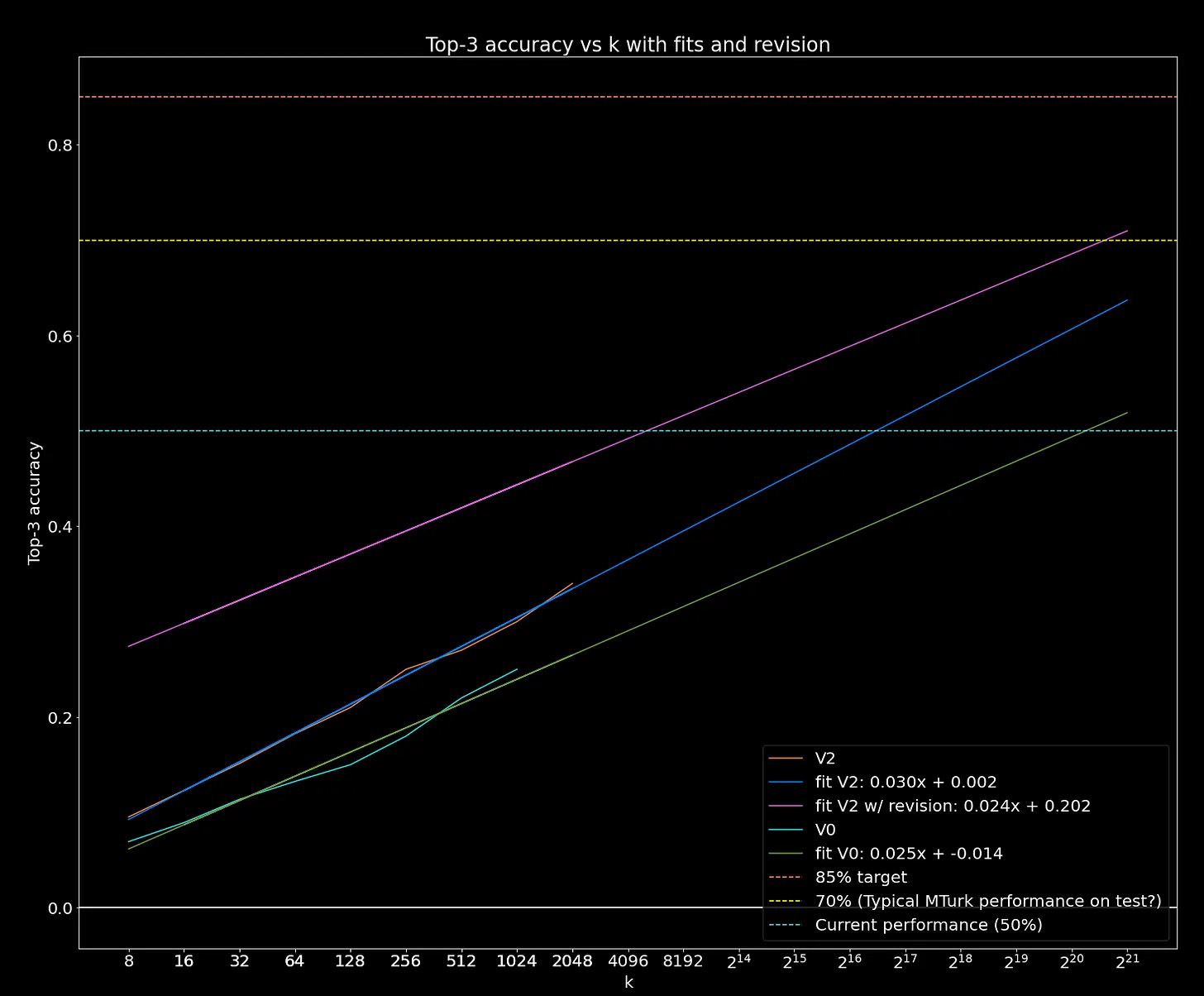
Ryan found an identical log-linear relationship between accuracy and test-time compute on ARC-AGI.
Does all this mean AGI is here if we just scale test-time compute? Not quite.
You can see similar exponential scaling curves by looking at any brute force search which is O(x^n). In fact, we know at least 50% of ARC-AGI can be solved via brute force and zero AI.
To beat ARC-AGI this way, you'd need to generate over 100 million solution programs per task. Practicality alone rules out O(x^n) search for scaled up AI systems.
Moreover, we know this is not how humans beat ARC tasks. Humans do not generate thousands of potential solutions, instead we use the perception network in our brains to "see" a handful of potential solutions and deterministically check them with system 2-style thinking.
We can get smarter.
New Ideas Are Needed
Intelligence can be measured by looking at how well a system converts information to action over a space of situations. It's a conversion ratio and thus approaches a limit. Once you have perfect intelligence, the only way to progress is to go collect new information.
There are a couple ways a less intelligent system could appear more intelligent without actually being more intelligent.
One way is a system that just memorizes the best action. This kind of system would be very brittle, appearing intelligent in one domain, but fall over easily in another.
Another way is through trial and error. A system might appear intelligent if it eventually gets the right answer, but not if it needs 100 guesses first.
We should expect future test-time compute research to look at how to scale search and refinement more efficiently, perhaps using deep learning to guide the search process.
That said, we don't believe this alone explains the big gap between o1's performance on ARC-AGI and other objectively difficult benchmarks like IOI or AIME.
A more sufficient way to explain this is that o1 still operates primarily within distribution of its pre-training data, but now inclusive of all the newly generated synthetic CoTs.
The additional synthetic CoT data increases focus on the distribution of CoTs as opposed to just the distribution of answers (more compute is spent on how to get the answer vs what is the answer). We expect to see systems like o1 do better on benchmarks that involve reusing well-known emulated reasoning templates (programs) but will still struggle to crack problems that require synthesizing brand new reasoning on the fly.
Test-time refinement on CoT can only correct reasoning mistakes so far. This also suggests why o1 is so impressive in certain domains. Test-time refinement on CoT gets an additional boost when the base model is pre-trained in a similar way.
Either approach alone would not get you the big leap.
In summary, o1 represents a paradigm shift from "memorize the answers" to "memorize the reasoning" but is not a departure from the broader paradigm of fitting a curve to a distribution in order to boost performance by making everything in-distribution.
We still need new ideas for AGI.
Take Action
Deep CoT integration is an exciting, new direction and there's much more to be discovered. ARC Prize exists to bring this energy to open source so that all can benefit from open AGI in our lifetime.
Do you have ideas on how to push these new ideas further? What about CoT with multi-modal, CoT with code generation, or combining program search with CoT?
Now is the time to jump into the action by participating in ARC Prize. Win top score prizes and paper awards and the attention and respect of millions.
Great ideas can come from anywhere. Maybe you?
Try hacking on o1 yourself starting with our default Kaggle notebook.
Sign up for ARC Prize to get notified when new high scores hit the leaderboard.