
ARC Prize Side Quest: SnakeBench
We tested 50 LLMs — from Haiku to o3-mini — to see which were the best at battling snakes.
Introducing SnakeBench, an experimental ARC Prize challenge of 2.8K head-to-head LLM snake games. Designed to test how models interact with dynamic environments, real-time decision-making and long-term strategy.

The mission of the ARC Prize Foundation is to pull open science forward. We do that by building and deploying frontier benchmarks which explore the gap between “easy for humans, hard for AI.”
We created our first benchmark, ARC-AGI-1, in 2019. Models did not achieve human-comparable performance until 2024. Building on ARC-AGI-1, we will release version 2 shortly.
Looking forward, explorations like SnakeBench help inform our benchmark design (v3+). Improving AI model performance necessitates that we expand beyond the input/output grid format of V1 & V2.
Future benchmarks will look materially different, allowing for more complex reasoning, goal setting, and the development of intuition within an environment. We are still in the design phase. Toy prototypes like this help shape our thinking.
What we learned about benchmark design
-
Reasoning models prevail: Reasoning models were in a league of their own. o3-mini and DeepSeek won 78% of the matches they played against other LLMs.
-
Context is crucial: Models require extensive data about the board to play well: full coordinates, locations of apples, positions of other snakes, and a clear explanation of how to parse the X/Y grid. This developer-intuition prompting highlights AI's current limitations.
-
Obvious mistakes made most games uninteresting: Most LLMs failed to understand the game board and track their snake's position, leading to collisions. It wasn’t until we tested GPT-4, Gemini 2.0, and o3-mini that we saw enough spatial reasoning for strategic play.
SnakeBench Leaderboard
| Rank | Model | ELO | Wins | Losses | Ties | Apples | View |
| 1 | o3-mini | 1825 | 155 | 21 | 21 | 546 | -> |
| 2 | DeepSeek-R1 | 1801 | 86 | 18 | 7 | 259 | -> |
| 3 | Meta-Llama-3.1-405B-Instruct-Turbo | 1731 | 70 | 30 | 10 | 228 | -> |
| 4 | claude-3-5-sonnet-20241022 | 1689 | 133 | 44 | 15 | 424 | -> |
| 5 | Meta-Llama-3-70B-Instruct-Turbo | 1681 | 63 | 37 | 10 | 123 | -> |
| 6 | o1-mini | 1672 | 119 | 56 | 17 | 414 | -> |
See the full 50 LLM leaderboard at SnakeBench.com. Code and results are open source.
Games Matter
ARC Prize's mission is to measure and guide AI toward bridging the gap between tasks that are "easy for humans, hard for AI." As long as we can create problems that humans can solve but AI cannot, we have not achieved AGI.
Games are excellent examples of easily verifiable domains that can measure AI's generalization capability. Plus…they’re fun to play.
Independent of our main benchmark (ARC-AGI-1), we ran this side quest to see how an LLM would do in Snake. This would force a model to:
- Track evolving states round by round
- Manage multiple objectives with dynamic objects (score points, avoid collisions)
- Evaluate spatial reasoning in a textual environment
Long history of testing LLMs in game environments
Researchers have used games to test how LLMs plan, adapt, and understand complex environments including:
- Text-Based Adventure Games: GPT-style models are used to play interactive fiction games (e.g. Zork-like environments) by reading textual descriptions and inputting commands.
- Embodied Simulation Tasks: Agents must execute sequences like “find a knife in the kitchen and put it in the drawer” in ALFWorld.
- Physical Robotics: Google’s PaLM-SayCan is an LLM-based robotic agent that plans real-world actions. It uses an LLM (PaLM) to suggest possible next steps given a high-level goal, and a value function to rank which actions are feasible.
- Board and Strategy Games: Meta’s CICERO combined an LLM with strategic planning to play the board game Diplomacy. Without special handling, LLMs were prone to making illegal or nonsensical moves because they don’t truly “see” the board – they only predict moves from text.
- Video Games and 3D Worlds: Voyager, an agent that uses GPT-4 to play Minecraft autonomously and of course the Agent57 Atari game player.
SnakeBench Methodology
Starting with the environment’s state (game description, sensor readings, etc.), a prompt was given to the LLM as context. The LLM then generates an action, left, right, up, or down.
Models that "thought" for longer before picking a move could gain more coherent long-horizon behavior and better performance. This means the LLM would internally deliberate (e.g. “I want to avoid that enemy snake so I should move away.”) and then output the action (e.g. “move away”).
For SnakeBench, we presented the board as a 2d grid to the LLM in plain text format, with rows labeled 0 to 9 from the bottom up, and columns labeled 0 to 9 from left to right. Apples, snake heads, and tails were denoted by different symbols.
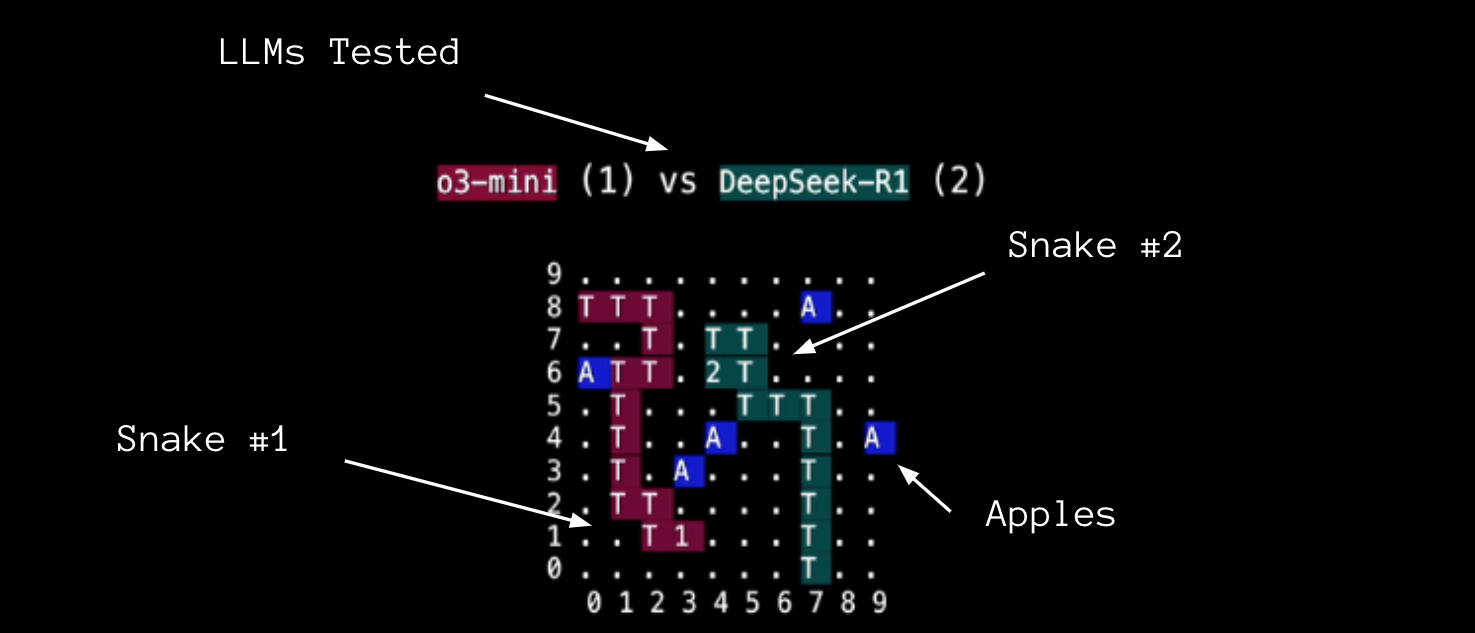
Each LLM was prompted for its move in each round. Moves were applied simultaneously, which introduced the possibility of head-on collisions.
If a snake landed on an apple, it scored a point and grew in length. If a snake collided with a wall or another snake’s body, it lost immediately.
Elo ratings were computed to rank how often a particular LLM won.
In addition to displaying the 2d board, additional information was included in the prompt:
- Coordinates of enemy positions
- Coordinates of self
- Apple coordinates
- Rationale from the LLMs last move
- Rules of the game
See below for a full prompt example.
This context-heavy prompt is also a key reason why reasoning models did much better. They are trained to do this thinking step prior to their output. Rather than artificially engineering a thinking step in the prompt, reasoning models do it automatically.
Below is a brief excerpt of DeepSeek’s chain-of-thought in one move (full version here).
DeepSeek’s “Thinking” key sections:
- Repeating known information about the board
- Evaluating possible directions
- Evaluating where apples are
- Evaluating where enemies are
- Making a proposed move (in this case down) and evaluating alternatives
- Confirming move
<think>
Okay, let's see. I need to figure out the best move for my snake. The board is 10x10,
and my snake is at (3,4). The apples are at (4,2), (3,3), (7,8), (0,9), (7,0). The
enemy snake is at (1,5) with an empty body, so it's just the head.
Looking at the apples: there's an apple at (3,3), which is directly DOWN from my
current position. If I move DOWN, I can eat that apple and grow. But wait, moving
DOWN would take me to (3,3), which is an apple. That's good for points. But I need
to make sure that moving there is safe. Are there any obstacles?
The enemy snake is at (1,5). Their body is empty, so they can move freely...
Another consideration: moving DOWN to (3,3) would get the apple, which is good. Then,
after eating, my snake would grow. So next turn, the body would include the previous
position. But for this move, since there's no body yet, moving into the apple is safe.
Other directions: UP to (3,5). That's an empty spot. No apple there...
Wait, but what about the enemy snake? They are at (1,5)...
So the best option seems to be moving DOWN to (3,3) to eat the apple. That gives a
point and grows the snake. But wait, when you eat an apple, you grow, so the next
move's body would include the previous position. But since the current body is just
the head, moving down would add a segment.
Alternatively, moving LEFT to (2,4) or RIGHT to (4,4) would not get an apple but
would be safe...
Therefore, the best move is DOWN to eat the apple at (3,3), gaining a point and
growing the snake. No immediate threats in that direction. The enemy is at (1,5),
which is not in the path. So I should go DOWN.
</think>
Next move: DOWN"
LLMs still have challenges
The performance demand of playing an interesting snake game is currently beyond the capabilities of LLMs. Though this will eventually change, we observed current challenges:
- Textual Format is difficult for spatial reasoning: Models treat the board layout as tokens, not a native 2d array. This caused frequent coordinate confusion: e.g., moving in the wrong direction or not realizing their snake’s head was overlapping with its own tail.
- Tiered Performance: Lower tier models like GPT-3.5 Turbo, Haiku, and others consistently died early—often within the first few turns. They rarely scored more than once. Whereas mid/high-end models like GPT-4, Gemini 2.0, o3-mini showed better spatial reasoning, occasionally maneuvering around obstacles, snatching apples, and extending the game duration.
- Long-Horizon Planning and Memory Limits: Dynamic environments often require a sequence of many correct decisions to achieve a goal. LLMs, however, lost focus over long sequences. To combat this, we injected the rationale from the LLM’s previous move so it had the chance to maintain some strategic stability.
- Brittleness to Novelty or Changes: LLMs proved to be brittle – small changes in input format or unfamiliar situations can break their reasoning.
Some of these issues could be mitigated by the developer through injecting more safeguards and knowledge into the prompt. For example, we could have restricted the possible moves of the LLM to only legal moves. However, the more developer intelligence you add to the model, the less you are testing its ability to reason and navigate, the core purpose of this exercise.
SnakeBench was a fun exploration into how LLMs handle dynamic environments and real-time decision making.
We look forward to exploring other game environments that can help us design better benchmarks to measure AI capabilities.
See the code here.
Appendix
Future Work
The SnakeBench environment could be improved by increasing the board size and adding more complex obstacles, like walls or more snake opponents. Introducing more snakes and apples would force greater competition and unpredictability, which would be useful for stress-testing LLM chain-of-thought reasoning. Additionally, continual improvements in prompting, through more structured or step-by-step prompts, could lead to fewer mistakes in reading board states.
o1-pro one shot
The initial snake game was produced by o1-pro in one shot. It effectively aced the environment's logic during tests, requiring minimal re-prompting of the game engine.
The prompt used:
Can you make me a snake game I can play?
but instead of an automatic timer it is turn based?
With an arbitrary amount of players, so multiple snakes.
Each snake will submit a turn they want to do, and then a "round" will happen.
Make a function that will ask each "player" what move they would like to make.
Multiple LLMs decide where they want to go. I want to make LLMs battle in snake.
Make the grid size arbitrary too.
I also need a way to replay the game, so make sure to store history state.
Google Models & Rate Limits:
Despite being on a paid tier, certain Google-based LLMs hit rate limits mid-game, which disrupted continuity. This caused many games not to finish. It was unclear how to remove the rate limits.
Prompting
We used a detailed prompt that included:
- Board Dimensions: Explicit min/max X and Y.
- Apple Positions: Listed as coordinate pairs.
- Enemy Snake Positions: IDs, heads, and body coordinates.
- Move History: Last move direction and rationale.
- Movement Rules: How to move up/down/left/right, scoring, and collision conditions.
View the full prompt here.