
We tested every major AI reasoning system. There is no clear winner.
Reflecting on Frontier AI Reasoning Systems
It's been six months since OpenAI achieved a breakthrough high score on ARC-AGI-1 with o3-preview. That moment marked the end of AGI scaling exclusively through pre-training. It's hard to overstate how strongly the industry led the public to believe that moment would never come.
As a concrete reminder, California contended with the SB-1047 AI safety senate bill last summer, predicated on urgent action necessary to curtail imminent danger from pre-training scaling. In a coicidence of history, OpenAI announced o1-preview one week before Governor Newsom vetoed the bill.
Fortuantely for AGI progress, the "vibe" has shifted to exploring new ideas. The leading idea, adopted now by every major lab, gives AI systems additional "time to think" at test-time. All frontier labs are using chain-of-thought (CoT) methods to accomplish this — DeepMind, OpenAI, xAI, DeepSeek, and even Anthropic who is a staunch proponent of pre-training scaling.
This has given rise to a new narrative: scaling up test-time compute (TTC) will get us to AGI. Let's examine this.
Test-Time Adaptation
Modern CoT usage leverages three distinct techniques.
1. Long-Running Inference
The first is simply letting the model generate tokens in a long-running continuous stream. These are sometimes a dedicated process model, other times a fine-tuned base model, but always trained explicitly to emulate human-reasoning traces via supervised fine-tuning. During inference, output tokens are fed back into the model. This gives rise to model's capability to pattern match against degenerate reasoning (e.g., noticing when CoT is caught in a loop) and to adopt explore vs exploit techniques all via a single long-running CoT.
2. Knowledge Recomposition
The second is to remix or recombine knowledge from the pre-trained or process model. Generally the goal here is to create a "better" CoT. One complete CoT can be thought of as a natural language program which maps a pre-trained model + input prompt to an ouput prompt. There are lots methods in use here and, outside of each lab, we can't be sure which AI systems are doing what – they don't share publicly. Most of the frontier algorithmic work is located in this step. Things like langauge-based program synthesis, CoT step voting, using grader models for feedback, backtracking, and more.
3. Parallel CoT Sampling
The last is wrapping techniques (1) and (2) above in a for loop and using a voting or conensus mechanism to arrive at a final result. For example, when we tested o3-preview we were instructed to use an additional sample parameter alongside the traditional reasoning_effort parameter. This appears to be a second-axis to scaling up TTC.
What we're seeing across all major AI reasoning systems: accuracy goes up as you stack these methods but efficiency goes way down. This gives rise to a CoT Pareto frontier on accuracy vs. cost using ARC as a consistent measuring stick.
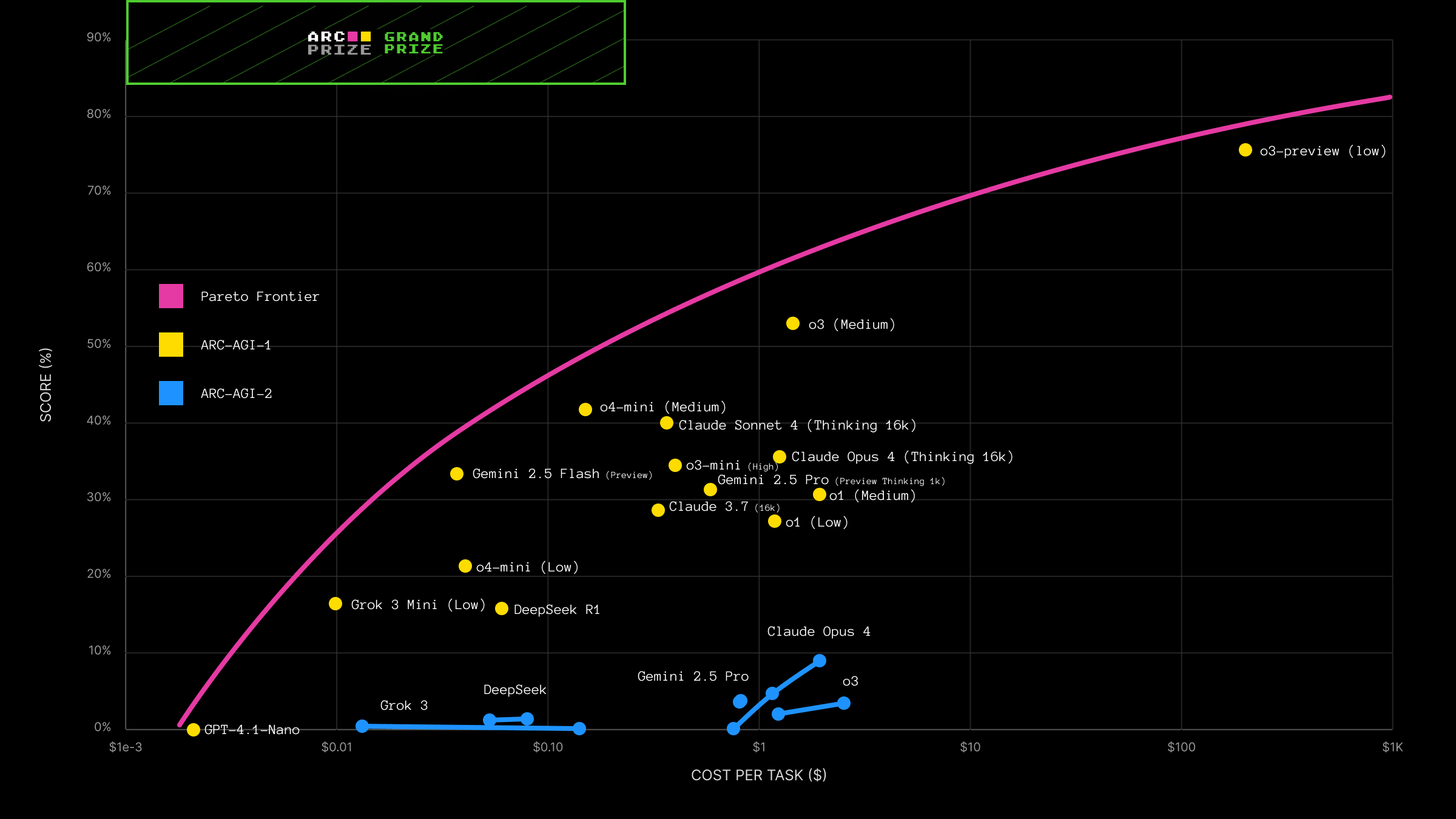
To make progress towards AGI, researchers are working to push this frontier closer to the green target box in the top-left corner which is our human baseline for joint accuracy and efficiency. I've made this point many times and will make it again here — all benchmark and model card reporting must be done along two axes, as you can "buy" additional accuracy. Naked accuracy scores are marketing, not science.
ARC-AGI-2 - the updated version of Chollet's original benchmark - remains completely unsolved. Here is our guidance: ARC-AGI-2 is a better tool for measuring breakthrough AGI capability progress, while ARC-AGI-1 is a better tool for comparing AI systems and measuring efficiency.


ARC-AGI-2, launched March 2025, and is designed to challenge AI reasoning systems. The fact that we're seeing such uniformly poor results on v2 strongly suggests all the frontier AI reasoning systems share common limitations.
No Clear Winner
We tested AI reasoning systems from every major lab and found a Pareto frontier for ARC-AGI-1, plus common and complete failure on ARC-AGI-2. We can now very confidently say: we still need new ideas for AGI!
Our findings strongly suggests there is no single universal winner or correct system to choose.
If you need the highest accuracy while sacrificing cost and time, OpenAI's o3-medium / o3-high (or upcoming o3-pro) are your best choice.
If you want a good balance of accuracy and cost, choose Google's Gemini 2.5 Flash.
If you want to just upgrade your AI applications from existing pure LLM models, you might want to start with xAI's Grok 3 mini-low. It gives a modest improvement on accuracy compared to much larger, and more expensive, pure LLMs.
ARC-AGI-1 Scores
| AI Reasoning System | Semi-Private Score | Cost per Task |
|---|---|---|
| o3-preview (low) | 75.7% | $200 |
| o3 (high) | 60.8% | $0.50 |
| o3-pro (high) | 59.3% | $4.16 |
| o4-mini (high) | 58.7% | $0.406 |
| Claude Sonnet 4 (Thinking 16k) | 40% | $0.366 |
| Claude Opus 4 (Thinking 16k) | 35.7% | $1.25 |
| Gemini 2.5 Flash (Preview) | 33.3% | $0.037 |
| Gemini 2.5 Pro (Preview) | 33.0% | $0.569 |
| DeepSeek R1 (5/28) | 21.2% | $0.046 |
| DeepSeek R1 | 15.8% | $0.06 |
| Grok 3 Mini (low) | 16.5% | $0.0099 |
| Grok 3 | 5.5% | $0.0093 |
| Llama 4 Maverick | 4.4% | $0.0078 |
| GPT-4.1-Nano | 0.0% | $0.002 |
ARC-AGI-2 Scores
| AI Reasoning System | Semi-Private Score | Cost per Task |
|---|---|---|
| Claude Opus 4 (Thinking 16k) | 8.6% | $1.93 |
| o3 (high) | 6.5% | $0.834 |
| o4-mini (high) | 6.1% | $0.856 |
| Claude Sonnet 4 (Thinking 16k) | 5.9% | $0.486 |
| o3-pro (high) | 4.9% | $7.55 |
| Gemini 2.5 Pro (Preview) | 3.8% | $0.813 |
| Gemini 2.5 Pro (Preview, Thinking 1k) | 3.4% | $0.804 |
| DeepSeek R1 | 1.3% | $0.08 |
| Grok 3 Mini Beta (low) | 0.4% | $0.013 |
| Grok 3 | 0.0% | $0.14 |
| Llama 4 Maverick | 0.0% | $0.012 |
See the ARC-AGI Leaderboard for results from more models/systems.
Reasoning Product-Market Fit?
Most AI reasoning system API providers offer both "synchronous" and "streaming" options patterned off of their /completions, or similar, endpoints. Our open source ARC-AGI testing harness only uses the "syncronous" option and we experienced consistent timeouts on ARC tasks at higher reasoning limits during testing.
Some providers like OpenAI are now offering new options like "background mode" to handle these kinds of failure. With Gemini, we observed that thinking budgets were treated as very loose guidelines, while Claude was better about holding to the budget.
While the industry rapidly converged on OpenAI's /completion API design in order to be cross-compatible, we're not seeing similar API or developer UX consensus emerge for long-running reasoning tasks. This plus the fact that "easy" ARC tasks are timing out on default API settings suggests a weaker degree of product-market fit relative to pure LLMs at the platform level.
Further evidence:
-
Zapier AI is seeing exponential usage growth driven by use case diffusion using pure LLMs, not AI reasoning systems.
-
OpenAI Codex and Claude Code, which leverage AI reasoning patterns, are very different in product shape while trying to solve the same end-user problem (automated coding).
-
OpenAI has stated they will merge their reasoning systems with pure LLMs in upcoming GPT-5 to reduce confusion. Users aren't universally preferring
o3over4o.
All this suggests that adoption for AI reasoning systems requires significant changes to product shape. You can't simply "hot swap" a pure LLM with an AI reasoning system and expect an improved product.
New Ideas Still Needed
The most promising new ideas all sit at the intersection of deep learning and program synthesis. Deep learning and LLMs are great at perception, intuition guidance, and function approximation with drawbacks including requiring a lot of data, inefficiency, and working only in-distribution.
Program synthesis is great at generalizing out of distribution given only a few datapoints, composition, and high efficiency with drawbacks including being very hard to discover longer programs.
Systems like AlphaProof, AlphaEvolve, and even o3 merge deep learning with program synthesis, though I'd say all fall on the side of the spectrum closer to deep learning.
What I think is exciting, and important, is that individual people and teams can have an unprecedented impact on humanity's future by working on new AGI ideas. And you can do it as an outsider. In fact, I believe there is no single point in human history where an individual person could have so much leverage over the future.
If you are a capable individual with new ideas, please work on AGI – and consider entering ARC Prize 2025!