The North Star for AGI
ARC Prize Foundation is a nonprofit advancing open-source artificial general intelligence research through benchmarks & prizes.
Enter ARC Prize 2026 Now $2,000,000 in prizes!
Top AI Leaders and Partners
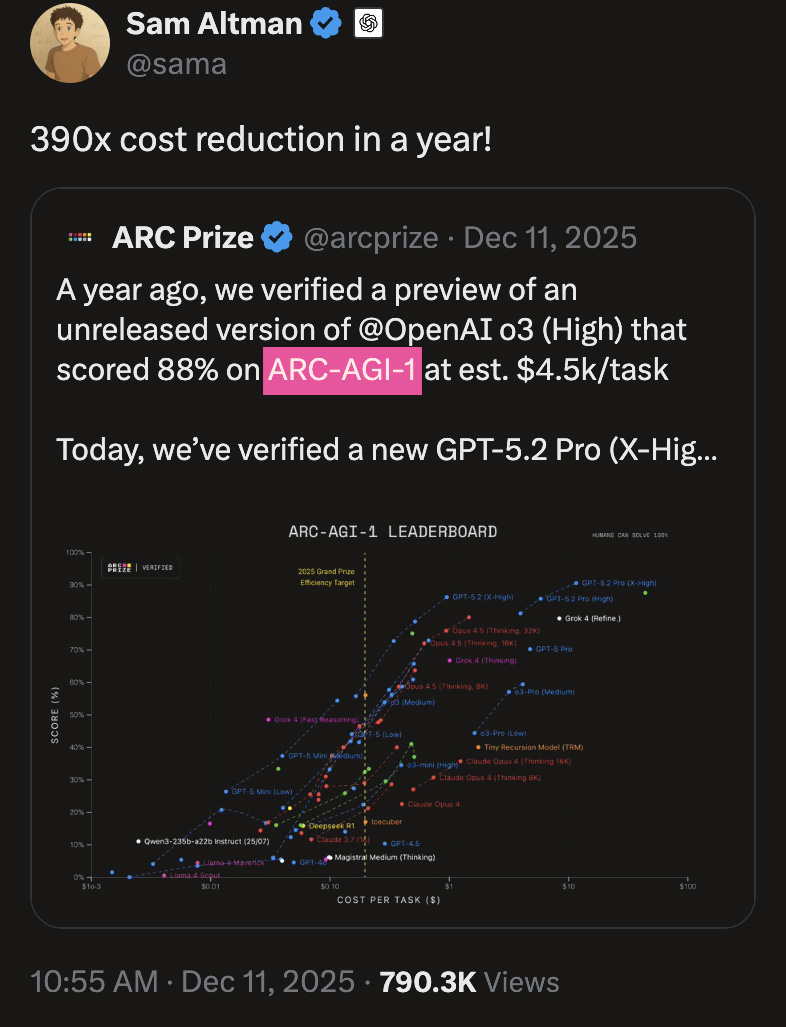
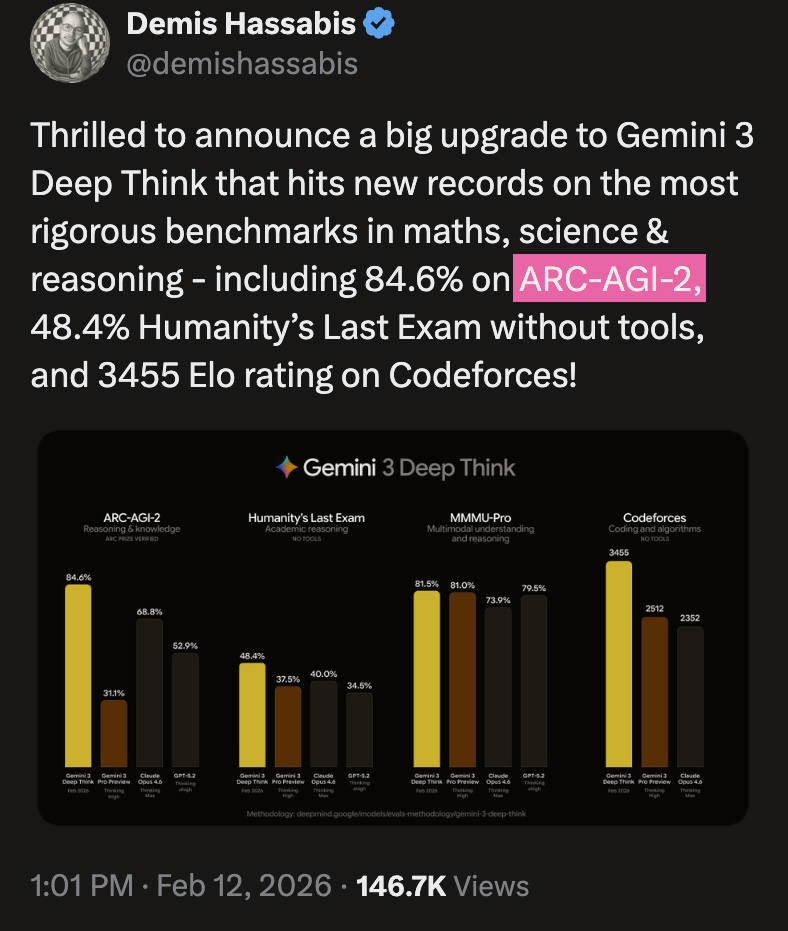
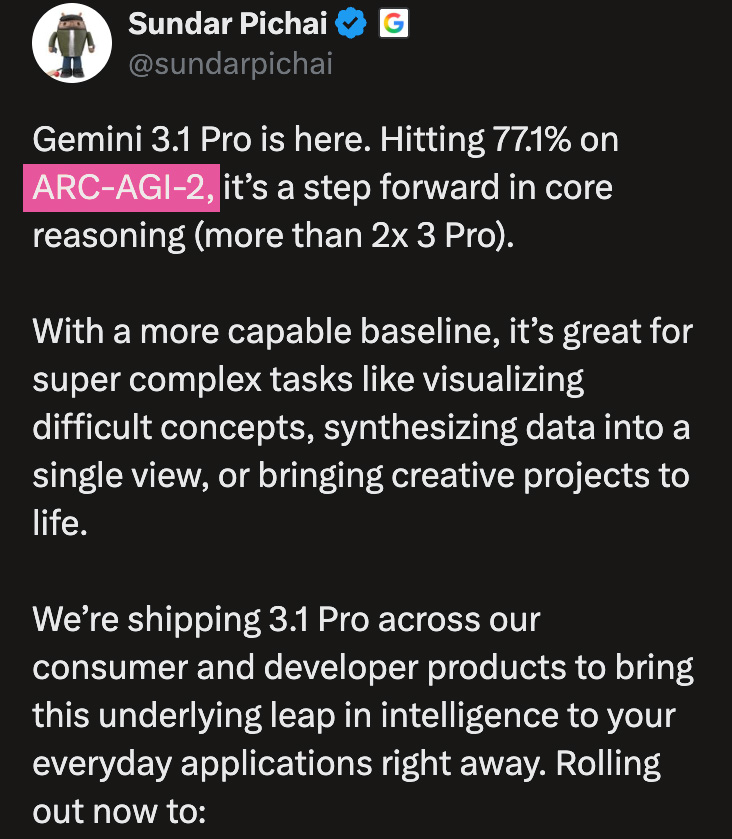
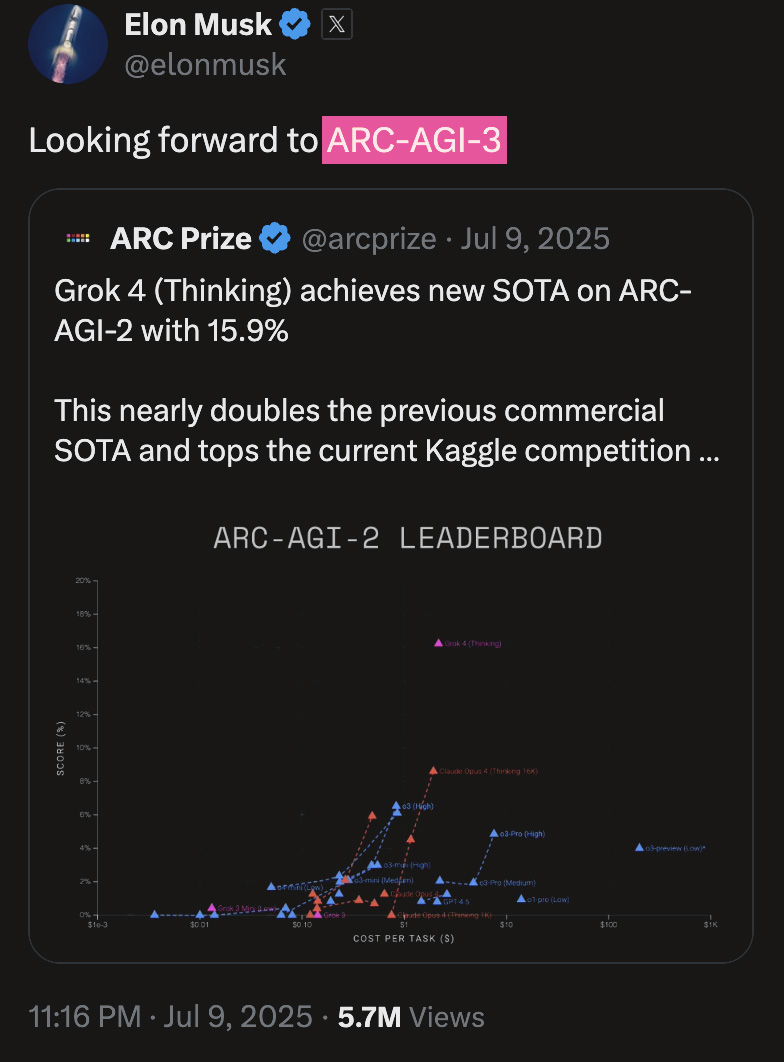
Low-Noise, High-Signal AGI Benchmarks
We build scientifically-grounded benchmarks that reveal the gap between what's easy for humans, hard for AI.
ARC-AGI has repeatedly identified key inflection points in AI progress, including the emergence of reasoning systems and the rise of capable AI agents.
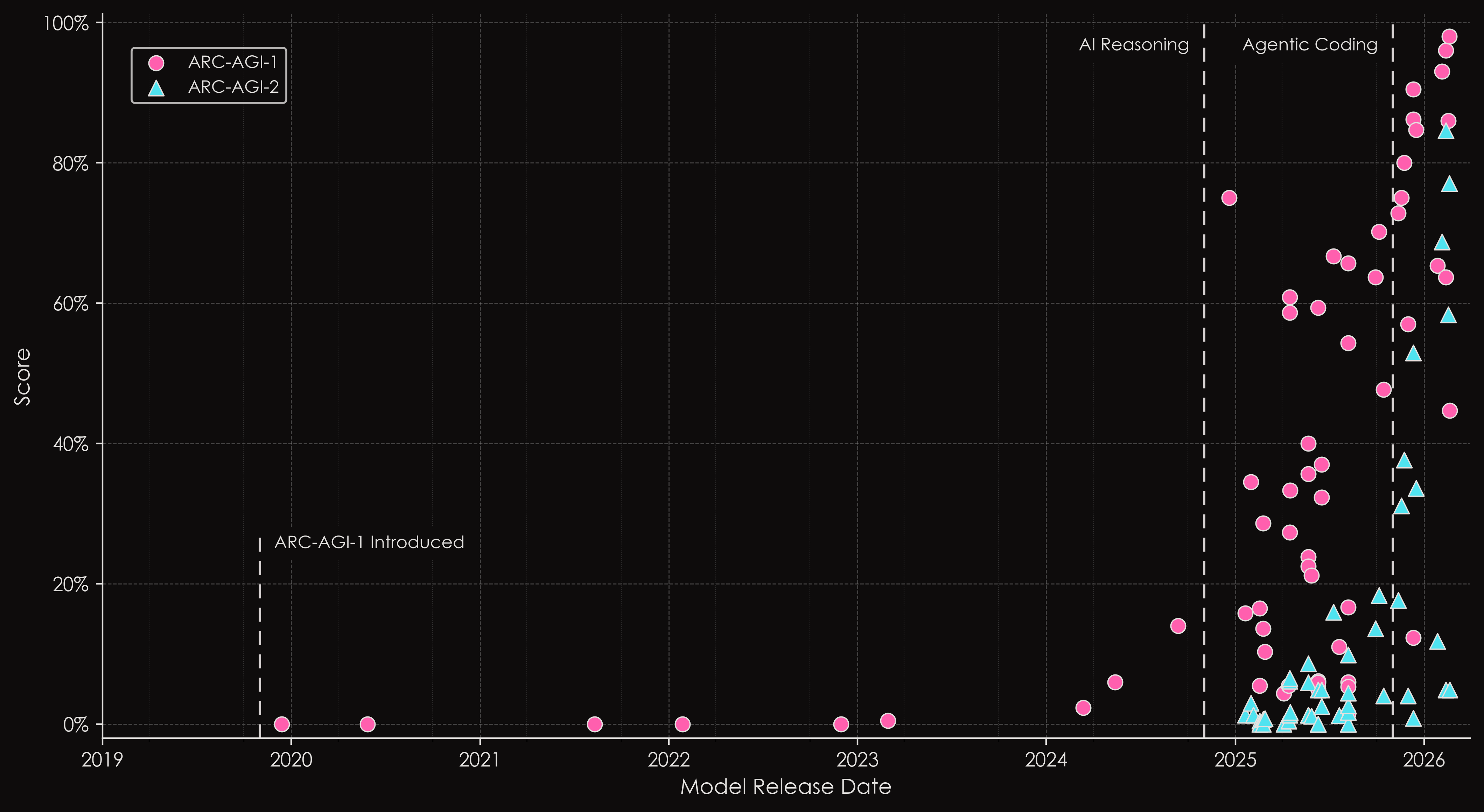
New ideas still needed for AGI.
While AI has made tremendous progress, ARC-AGI shows us scaling alone will not reach AGI.
Our mission is simple: guide research, accelerate progress, and ensure the path to AGI remains open and accessible to all.
We define AGI as a system that can match the learning efficiency of humans.
Introducing ARC-AGI-3. The world's only unbeaten benchmark that measures agentic intelligence.
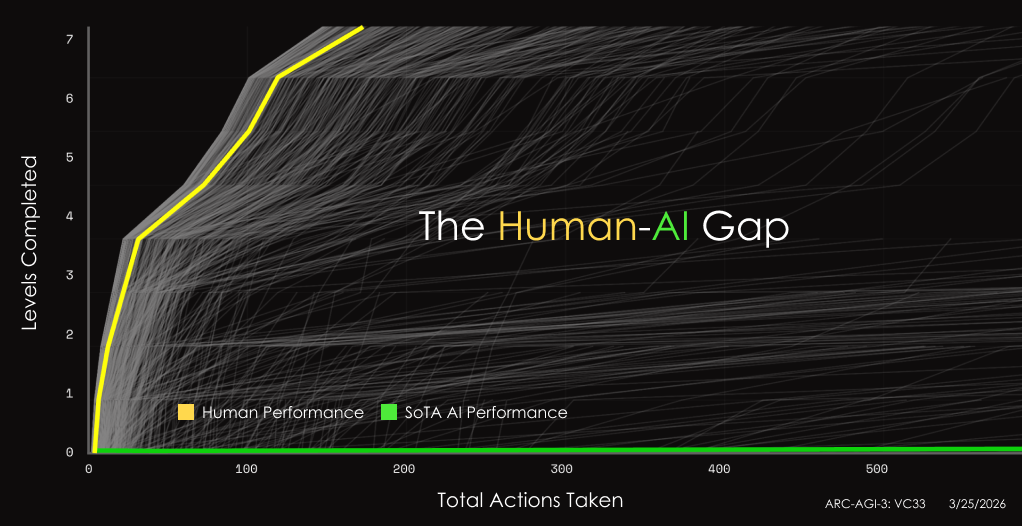
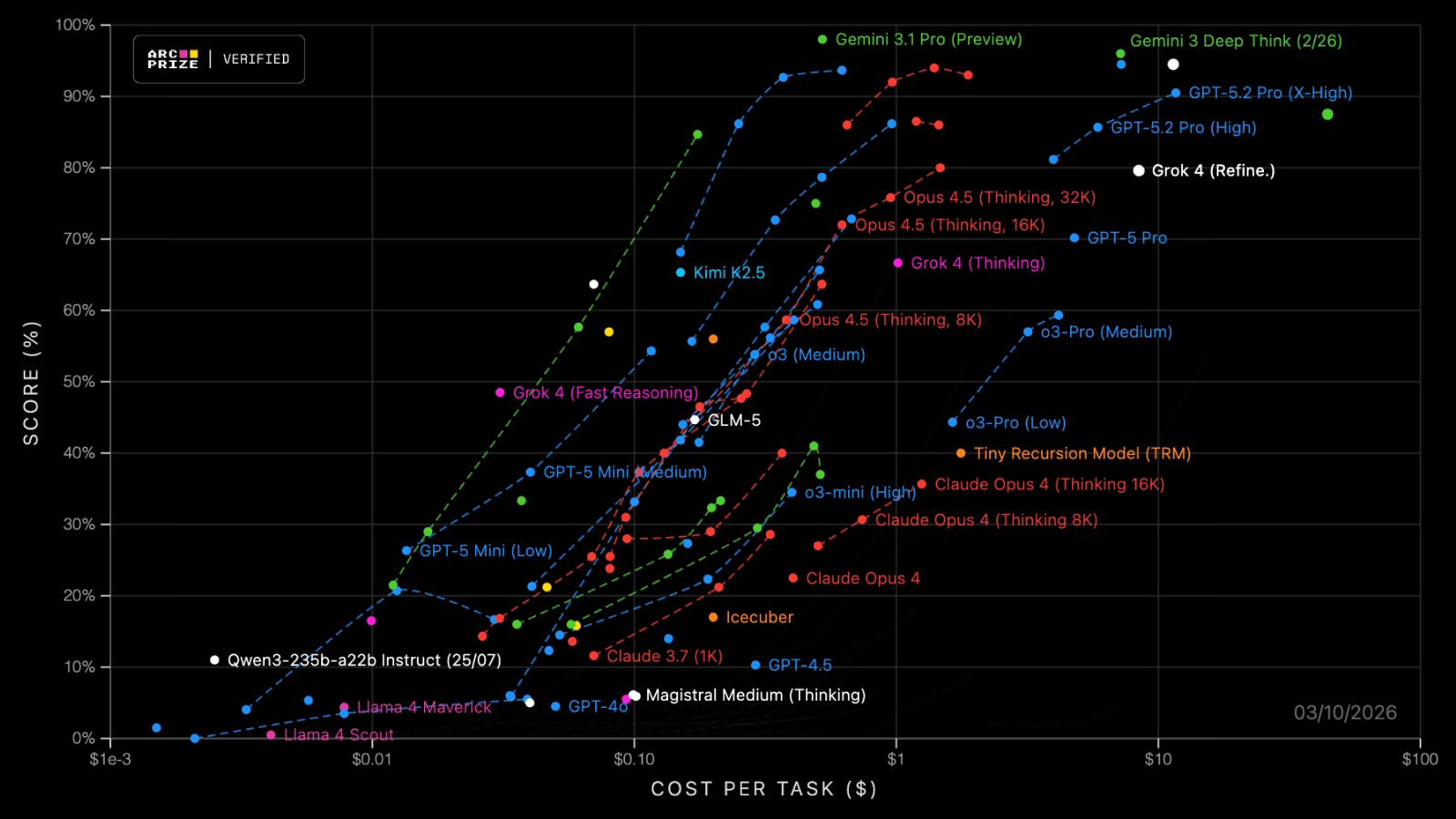
ARC-AGI Benchmark Series
Trusted by the world's leading AI labs and top academic researchers, explore the only benchmark that measures fluid intelligence. It's easy for humans, hard for AI.
Big ideas. Big money.
Get rewarded for open sourcing novel progress. In partnership with Kaggle, over $2M is up for grabs.

Founder Message
“AGI is the most important technology humanity will create, and we believe it is achievable in our lifetime. But ARC shows us we still need new ideas. Maybe they'll come from you?”
Mike Knoop (Zapier, Ndea) & François Chollet (Keras, Ndea, ARC-AGI)