ARC-AGI-2
2025 - Challenges Reasoning Models
Links
About
ARC-AGI-1 was created in 2019 (before the rise of LLMs). It endured five years of global competitions, a 50,000x scale-up of base LLMs, and saw little progress until late 2024, with the introduction of test-time adaptation methods pioneered by ARC Prize 2024 entrants and OpenAI.
ARC-AGI-2 - the next iteration of the benchmark - is designed to stress-test the capabilities of state-of-the-art AI reasoning systems, provide useful signal on AGI progress, and inspire researchers to work on new ideas.
Can you create a system that can reach 85% accuracy?
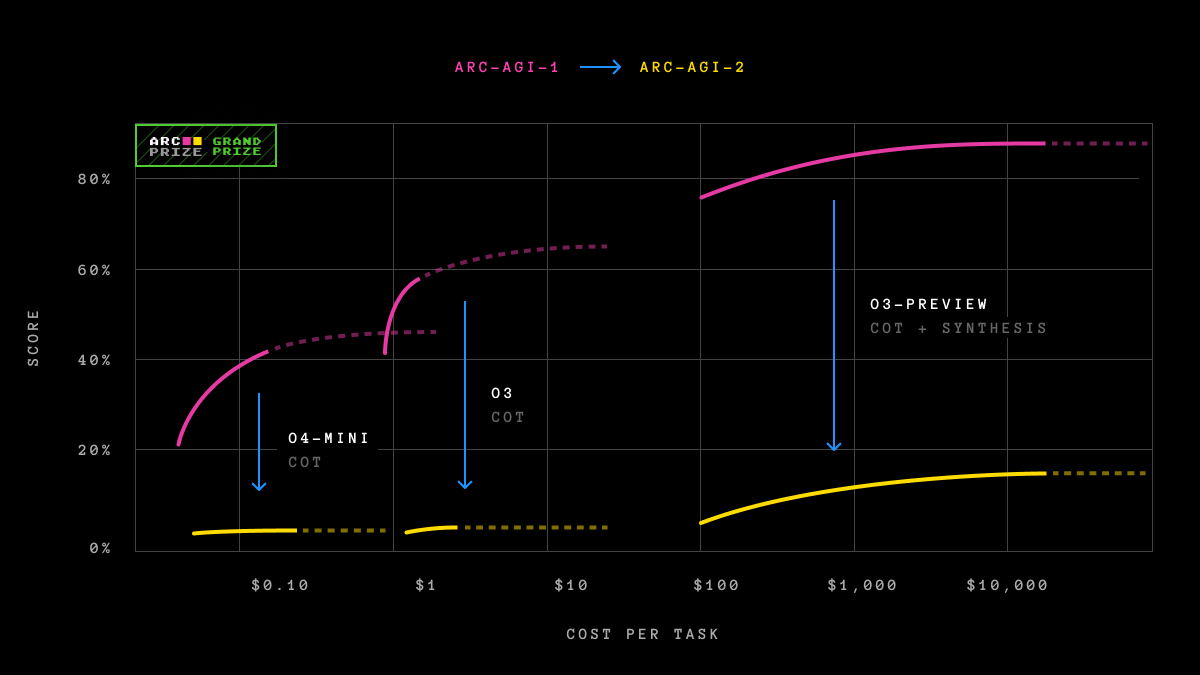
Efficiency Test
ARC-AGI-2: Scale is Not Enough
Log-linear scaling is insufficient to beat ARC-AGI-2.
New test-time adaptation algorithms or novel AI systems are needed to bring AI efficiency inline with human performance.
Capability Test
ARC-AGI-2: Symbolic Interpretation
Tasks requiring symbols to be interpreted as having meaning beyond their visual patterns.
Current systems attempt to check symmetry, mirroring, and other transformations, and even recognize connecting elements, but fail to assign semantic significance to the symbols themselves.

Capability Test
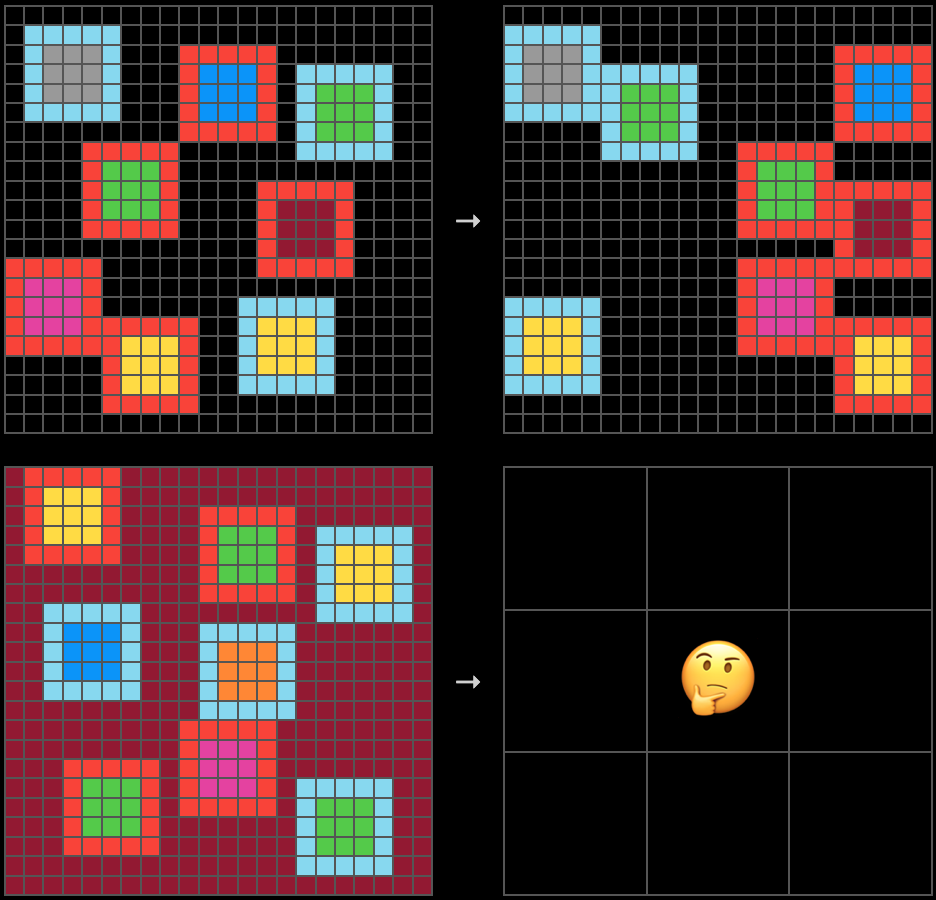
ARC-AGI-2: Compositional Reasoning
Tasks requiring simultaneous application of a rules, or application of multiples rules that interact with each other.
In contrast, if a task has very few global rules, current systems can consitently discover and can apply them.

Capability Test
ARC-AGI-2: Contextual Rule Application
Tasks where rules must be applied differently based on context.
Systems tend to fixate on superficial patterns rather than understanding the underlying selection principles.
Dataset Structure
| Dataset | Tasks | Description |
Training Set | 1000 tasks | Uncalibrated, public, a spectrum of difficulty ranging from very easy to very difficult for both humans and AI, designed to expose and teach Core Knowledge Priors, use to train your systems. |
Public Eval Set | 120 tasks | Calibrated, public, all tasks solved pass@2 by at least two humans, use to test your systems. |
| Semi-Private Eval Set | 120 tasks | Calibrated, not public, all tasks solved pass@2 by at least two humans, used for Kaggle live contest leaderboard and ARC Prize leaderboard. "Semi" means these tasks may have been exposed to limited third-parties eg. via API |
| Private Eval Set | 120 tasks | Calibrated, not public, all tasks solved pass@2 by at least two humans, used for Kaggle final contest leaderboard. "Private" means these tasks have not been exposed to third-parties. |
Calibration
The eval sets (Public, Semi-Private, Private) are "calibrated," meaning tasks are statistically similar (IDD). Scores are comparable across these sets (<1pp expected), assuming no overfitting. Calibration was done via controlled human testing (400+ participants) and existing AI testing.
To ensure calibration of human-facing difficulty, we conducted a live-study in San Diego in early 2025 involving over 400 members of the general public. Participants were tested on ARC-AGI-2 candidate tasks, allowing us to identify which problems could be consistently solved by at least two individuals within two or fewer attempts. This first-party data provides a solid benchmark for human performance and will be published alongside the ARC-AGI-2 paper.
100% of tasks have been solved by at least 2 humans (many by more) in under 2 attempts.
Efficiency Measurement:
Starting with ARC-AGI-2, all ARC-AGI reporting comes with an efficiency metric. We are started with cost because it is the most directly comparable between human and AI performance.
Intelligence is not solely defined by the ability to solve problems or achieve high scores. The efficiency with which those capabilities are acquired and deployed is a crucial, defining component. The core question being asked is not just "can AI acquire skill to solve a task?", but also at what efficiency or cost?
We know that brute-force search could eventually solve ARC-AGI (given unlimited resources and time to search), this would not represent true intelligence. Intelligence is about finding the solution efficiently, not exhaustively.
This focus on efficiency is a core principle behind the ARC-AGI. We will now explicitly quantify the cost of intelligence, requiring solutions to demonstrate not just capability, but also the efficient use of resources that defines general intelligence.
ARC-AGI-2 changelog:
- All eval sets (public, semi-private, private) now contain 120 tasks (up from 100)
- Removed tasks from eval sets that were susceptible to brute force search (all solved tasks from original 2020 Kaggle contest)
- Performed controlled human testing to calibrate eval set difficulty to ensure IDD and verify pass@2 solvability by at least 2 humans (to match AI rules)
- Designed new tasks to challenge AI reasoning systems based on study (symbolic interpreation, compositional reasoning, contextual rules, and more)
For more information, read the ARC-AGI-2 launch post.