
ARC-AGI-2 + ARC Prize 2025 is Live!


Level Up to Reach AGI
Good AGI benchmarks act as useful progress indicators. Better AGI benchmarks clearly discern capabilities. The best AGI benchmarks do all this and actively inspire research and guide innovation.
At ARC Prize, our mission is to serve as a North Star towards AGI through enduring benchmarks, directing efforts towards systems capable of general intelligence and significantly compressing the timeline for scientific breakthroughs.
ARC-AGI-1 has measured progress towards AGI since 2019 and was the only benchmark to pinpoint the exact moment in late 2024 when AI moved beyond pure memorization. OpenAI used ARC-AGI-1 to demonstrate this progress with their o3-preview system which combines deep learning-based LLMs with reasoning synthesis engines.
ARC Prize 2024 inspired thousands of independent students and researchers to work alongside frontier labs on new test-time adaption ideas.
But there is more work to do to reach AGI. AGI still needs new ideas.
We can characterize systems like o3-preview as going from "zero to one" on the fluid intelligence spectrum. But these systems are highly inefficient and currently require significant human supervision during the training process to adapt to new domains.
Announcements
Today we’re excited to launch ARC-AGI-2 to challenge the new frontier. ARC-AGI-2 is even harder for AI (in particular, AI reasoning systems), while maintaining the same relative ease for humans. Pure LLMs score 0% on ARC-AGI-2, and public AI reasoning systems achieve only single-digit percentage scores. In contrast, every task in ARC-AGI-2 has been solved by at least 2 humans in under 2 attempts.
Alongside it, today we're launching ARC Prize 2025, designed to drive open-source progress on highly efficient, general systems capable of beating ARC-AGI-2.
Easy for Humans, Hard for AI
All other AI benchmarks focus on superhuman capabilities or specialized knowledge by testing "PhD++" skills. ARC-AGI is the only benchmark that takes the opposite design choice -- by focusing on tasks that are relatively easy for humans, yet hard, or impossible, for AI, we shine a spotlight on capability gaps that do not spontaneously emerge from "scaling up".
The ARC Prize Foundation adapts this into our definition for measuring AGI: the gap between the set of tasks that are easy for humans and hard for AI. When this gap is zero, when there are no remaining tasks, we can find that challenge AI, we will have achieved AGI.
Addressing these capability gaps requires novel insight and new ideas. Importantly, ARC-AGI does not exist purely to measure AGI progress. It also exists to inspire researchers to work on new ideas.
Intelligence requires the ability to generalize from limited experience and apply knowledge in new, unexpected situations. AI systems are already superhuman in many specific domains (e.g., playing Go and image recognition.) However, these are narrow, specialized capabilities. The "human-ai gap" reveals what's missing for general intelligence - highly efficiently acquiring new skills.
Introducing ARC-AGI-2
The ARC-AGI-2 benchmark launches today. This second edition in the ARC-AGI series raises the bar for difficulty for AI while maintaining the same relative ease for humans.
Every ARC-AGI-2 task was solved by at least 2 humans in 2 attempts or less in a controlled study with hundreds of human participants. This matches the rules we hold for AI, which gets two attempts per task.
ARC-AGI-1, introduced in 2019, was designed to challenge deep learning. Specifically, it was designed to resist the ability to simply "memorize" the training dataset. ARC-AGI comprises a training dataset and several evaluation sets, including a private eval set used for the ARC Prize 2024 contest. The training set is intended to teach the Core Knowledge Priors required to solve tasks in the evaluation sets. To solve the evaluation tasks, AI systems must demonstrate basic fluid intelligence or the ability to adapt to novel, never-before-seen tasks.
As an analogy, think of the training set as a way to learn grade school math symbols, and the evaluation set requires you to solve algebra equations using your knowledge of those symbols. You cannot simply memorize your way to the answer, you must apply existing knowledge to new problems.
Any AI system capable of beating ARC-AGI-1 demonstrates a binary level of fluid intelligence. In contrast, ARC-AGI-2 significantly raises the bar for AI. To beat it, you must demonstrate both a high level of adaptability and high efficiency.
While designing ARC-AGI-2, we studied these properties of frontier AI reasoning systems. Below are example tasks to illustrate some of what we discovered. All of the following tasks are part of ARC-AGI-2 and were (1) solved by at least 2 humans in under 2 attempts and (2) unsolved by any frontier AI reasoning system.
Note: special thank you to the ARC Prize community for contributing to this analysis, including Mace, Mikel, and many members in the ARC Prize Discord.
Still Hard for AI
Symbolic Interpretation
We found that frontier AI reasoning systems struggle with tasks requiring symbols to be interpreted as having meaning beyond their visual patterns. Systems attempted symmetry checking, mirroring, transformations, and even recognized connecting elements, but failed to assign semantic significance to the symbols themselves.

Compositional Reasoning
We found AI reasoning systems struggle with tasks requiring simultaneous application of rules, or application of multiple rules that interact with each other. In contrast, if a task only has one, or very few, global rules, we found these systems can consistently discover and apply them.
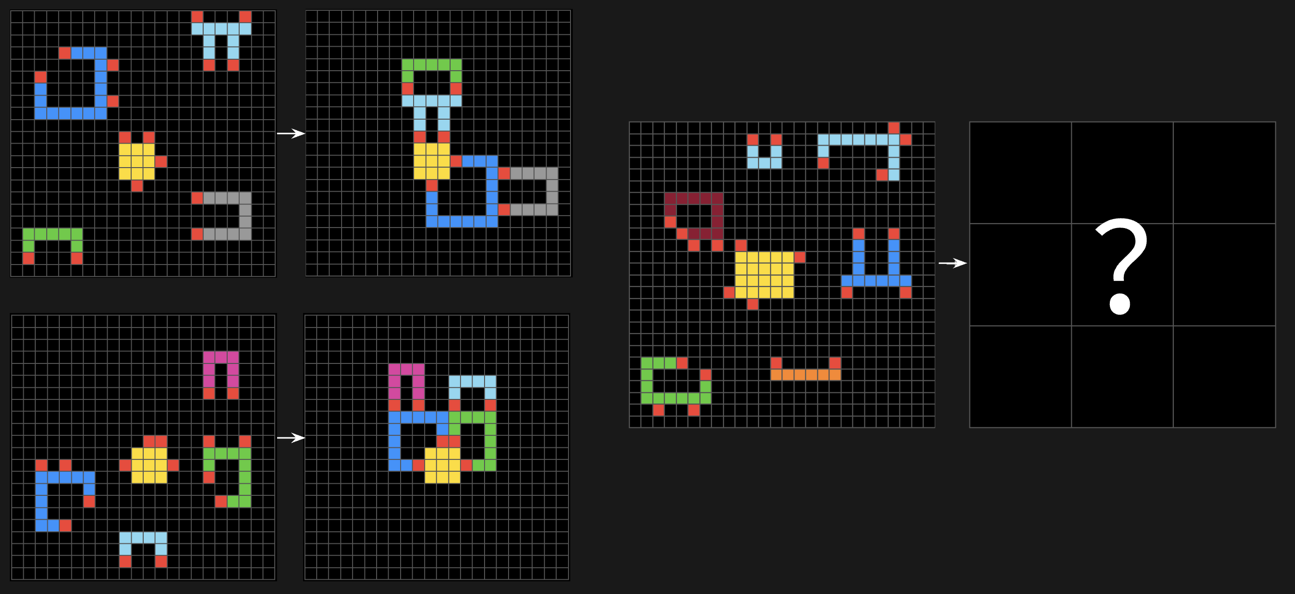
Contextual Rule Application
We found AI reasoning systems struggle with tasks where rules must be applied differently based on context. Systems tend to fixate on superficial patterns rather than understanding the underlying selection principles.

Datasets
ARC-AGI-2 is comprised of the following datasets:
| Dataset | Task Quantity | Calibration | Visibilty | Description |
|---|---|---|---|---|
| Training | 1000 | Uncalibrated | Public | A spectrum of difficulty ranging from very easy to very difficult for both humans and AI, designed to expose and teach Core Knowledge Priors; use to train your system. |
| Public Eval | 120 | Calibrated | Public | All tasks solved pass@2 by at least two humans; use to test your system. |
| Semi-Private Eval | 120 | Calibrated | Private | All tasks solved pass@2 by at least two humans, used for the Kaggle live contest leaderboard and ARC Prize leaderboard. "Semi" means these tasks may have been exposed to limited third-parties (e.g., via API.) |
| Private Eval | 120 | Calibrated | Private | All tasks solved pass@2 by at least two humans, used for Kaggle final contest leaderboard. "Private" means these tasks have not been exposed to third-parties. |
Calibrated means that these tasks are IDD (independent and identically distributed). In principle, non-overfit scores across the public, semi-private, and private eval sets should be directly comparable. To gather these data, we tested with over 400 humans live in a controlled setting. Human solvability data for public tasks will be open-sourced alongside the ARC-AGI-2 paper in the coming weeks.
Like ARC-AGI-1, ARC-AGI-2 uses a pass@2 measurement system to account for the fact that certain tasks have explicit ambiguity and require two guesses to disambiguate. As well as to catch any unintentional ambiguity or mistakes in the dataset. Given controlled human testing with ARC-AGI-2, we are more confident in the task quality compared to ARC-AGI-1.
Here's the official changelog for ARC-AGI-2:
- All eval sets (public, semi-private, private) now contain 120 tasks (up from 100).
- Removed tasks from eval sets that were susceptible to brute force search (all solved tasks from the original 2020 Kaggle contest).
- Performed controlled human testing to calibrate eval set difficulty to ensure IDD and verify pass@2 solvability by at least 2 humans (to match AI rules).
- Designed new tasks to challenge AI reasoning systems based on study (symbolic interpretation, compositional reasoning, contextual rules, and more).
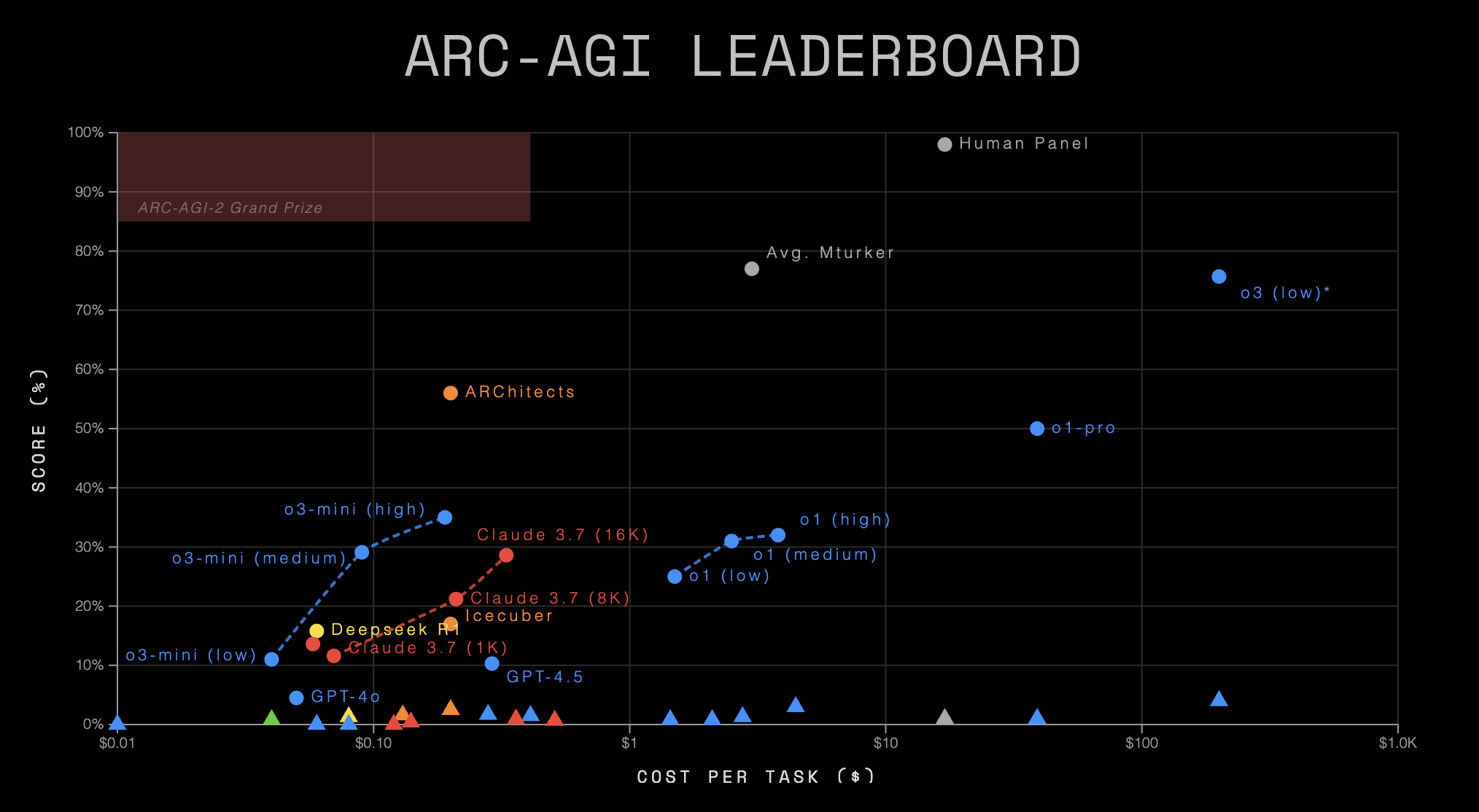
We've also re-evaluated ARC-AGI-2 against all public AI systems. Here are the starting scores.
| System | ARC-AGI-1 | ARC-AGI-2 | Efficiency (cost/task) |
| Human panel (at least 2 humans) | 98% | 100% | $17 |
| Human panel (average) | 64.2% | 60% | $17 |
| o3-preview-low (CoT + Search/Synthesis) | 75.7% | 4%* | $200 |
| o1-pro (CoT + Search/Synthesis) | ~50% | 1%* | $200* |
| ARChitects (Kaggle 2024 Winner) | 53.5% | 3% | $0.25 |
| o3-mini-high (Single CoT) | 35% | 0.0% | $0.41 |
| r1 and r1-zero (Single CoT) | 15.8% | 0.3% | $0.08 |
| gpt-4.5 (Pure LLM) | 10.3% | 0.0% | $0.29 |
Scores labeled with * are in-progress estimates based on partial results we've been able to aggregate so far and o1-pro pricing. Full results will be published once available.
All scores reported pass@2 and on the semi-private eval set (except ARC-AGI-1 human panel and ARChitects, which used public and private eval, respectively).
Human panel efficiency is based upon a $115-150 show-up fee, plus a $5/task solve incentive. We optimized costs to produce show-ups (only 70% of registrations actually showed up). Even though we believe the true limit to human intelligence cost efficiency is likely in the $2-5/task range, we report $17/task to reflect the actual data we collected.
We are looking forward to testing the production version of OpenAI o3-preview low/high once API access is available. Using ARC-AGI-1 tasks that transferred to ARC-AGI-2, we estimate that o3-preview-low would score ~4% and o3-high would potentially score up to 15-20% with very high compute (thousands of dollars per task).
Intelligence Is Not Just Capability
Going forward, all ARC-AGI reporting will come along with an efficiency metric. We are starting with cost because it is the most directly comparable between human and AI performance.
Intelligence is not solely defined by the ability to solve problems or achieve high scores. The efficiency with which those capabilities are acquired and deployed is a crucial, defining component. The core question being asked is not just, "Can AI acquire skill to solve a task?" but also, "At what efficiency or cost?"
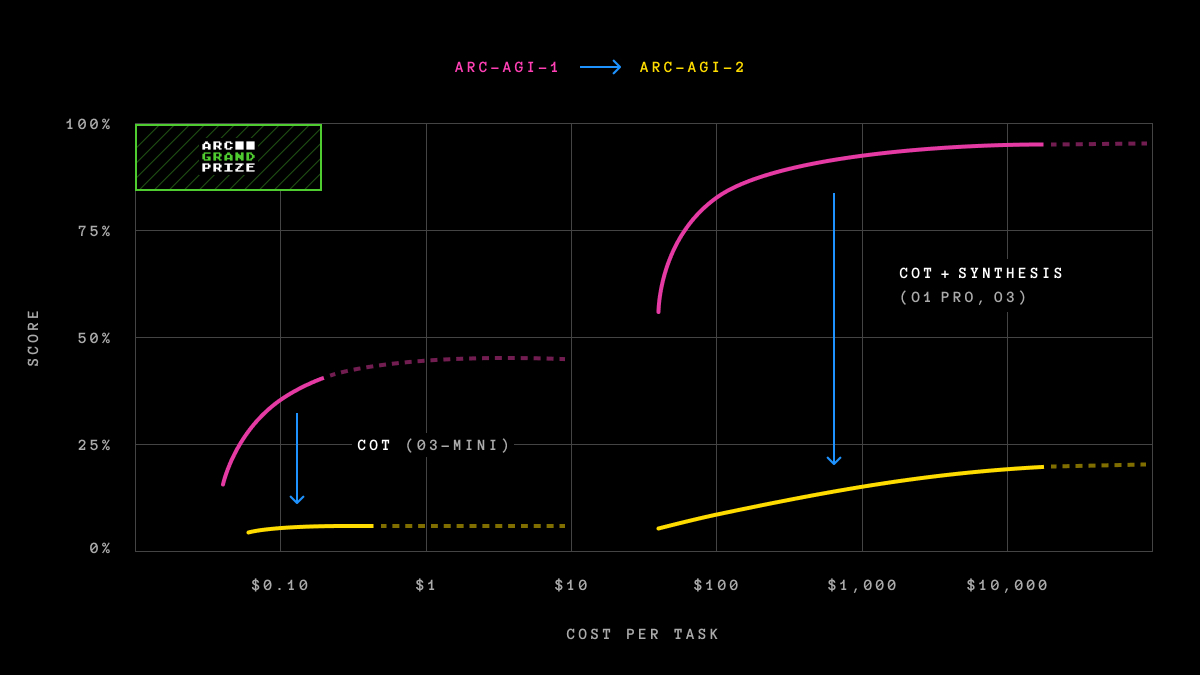
We know that brute-force search could eventually solve ARC-AGI (given unlimited resources and time to search). This would not represent true intelligence. Intelligence is about finding the solution efficiently, not exhaustively.
This focus on efficiency is a core principle behind the ARC-AGI. We will now explicitly quantify the cost of intelligence, requiring solutions to demonstrate not just capability, but also the efficient use of resources that defines general intelligence.
Our new leaderboard page reports progress along both a score and cost axis.
Competition Now Open! $1,000,000 in Prizes
Alongside ARC-AGI-2, we're excited to announce ARC Prize 2025 is now live! The contest is hosted on Kaggle and is open March 26 through November 3. The competition goes live later this week, sign up here to get notified.
There is $125K in guaranteed progress prizes, with an additional $700K Grand Prize (up $100k from last year!) waiting to be unlocked by a solution that scores greater than 85%, as well as $175K to-be-announced prizes.
Unlike the public leaderboard on arcprize.org, Kaggle rules restrict you from using internet APIs, and you only get ~$50 worth of compute per submission. In order to be eligible for prizes, contestants must open source and share their solution and work into the public domain at the end of the competition.
Last year's competition saw incredible success — over 1,500 teams participated, generating 40 influential research papers. ARC Prize-winning researchers introduced innovations now adopted across the AI industry.
What progress can you unlock and share with the world this year?
Prize Categories
Grand Prize ($700K)\ Unlocked once first team reaches 85% within Kaggles efficiency limits.
Top Score Prize ($75K)\ Awarded to the highest-scoring submissions.
Paper Prize ($50K)\ Awarded to the submission demonstrating the most significant conceptual progress toward solving ARC-AGI. Papers must be tied to a scored submission, but innovative ideas matter more than achieving a high score.
To-be-announced Prizes ($175k)More details on these coming during the 2025 competition.
You can find more details on our Competition page.
Changelog
Here's a quick look at the competition changelog from 2024 to 2025.
- ARC-AGI-2: we've replaced the ARC-AGI-1 dataset going forward.
- New leaderboard reporting: The Kaggle live contest leaderboard will report scores on semi-private, with final prize results reported one time on the private eval after content closes.
- Stronger open-source provisions: teams will be required to open source their solutions before receiving official private eval set scores.
- More compute: 2x compute vs. 2024 (L4x4s), about $50 worth now.
- More overfit prevention: we've made additional changes to score reporting on Kaggle to reduce data mining and overfiting and to incentivize conceptual progress.
Progress Depends On New Ideas — Maybe Yours?
The current state of AI operates in an idea-constrained environment. The next breakthrough might not come from a major AI lab but from a new, creative approach from someone like you.
If you're driven by curiosity, inspired by complexity, and committed to the rigorous pursuit of genuine general intelligence, ARC Prize 2025 is your opportunity.
Join us in the pursuit of open science.
Ready to get started?
Good luck! We can't wait to see what you build.