
Analyzing GPT-5.5 & Opus 4.7 with ARC-AGI-3

AI benchmarks can be incredible tools, but they usually only tell you if a model passed or failed. With ARC-AGI-3, however, we can see the thought process behind the score, not just the outcome.
This week we went through 160 replays and reasoning traces from OpenAI’s GPT-5.5 and Anthropic’s Opus 4.7 attempting novel, long-horizon environments. The scores were just one data point, but the interesting story is how they achieved their score.
Today we’re open-sourcing our analysis package.
| Model | ARC-AGI-3 Score* | Public Demo Replays |
|---|---|---|
| GPT-5.5 | 0.43% | Link |
| Opus 4.7 | 0.18% | Link |
* Scores tested with the semi-private dataset
With ARC-AGI-3 we can replay every action alongside the model's reasoning to see where it formed a hypothesis, where it abandoned a correct one, where it locked onto a wrong idea and couldn't let go.
We found 3 common failure modes:
- True Local Effect, False World Model - The models understand which action produced a change, but they fail to translate the effect into a global rule
- Wrong Level of Abstraction From Training Data - The models mistake an ARC-AGI-3 environment for another game
- Solved The Level, Didn’t Learn The Game - Even if a model beat a level, it’s unable to use that reward signal to enforce the correct actions
ARC-AGI-3 as an analysis tool
ARC-AGI-3 is a series of 135 novel environments. Each was hand-crafted by a human to test the ability of AI models to adapt to novelty. Play them yourself or watch our launch video.
The test-takers, whether human or AI, are not given instructions on how to play an environment. To make progress they must:
- Explore unfamiliar interfaces
- Infer rules from sparse feedback (aka world model)
- Form & test hypotheses
- Recover from wrong assumptions
- Transfer what they learned from one level to the next (aka continual learning)
Each environment is built without the cultural knowledge a model would usually lean on. This means the environments isolate abstract reasoning.
You can think of ARC-AGI-3 as the lowest common denominator across novelty, ambiguity, planning, and adaptation. These are the same demands real-world tasks make of agents.



ar25, lf52, sb26Failure modes on ARC-AGI-3
ARC-AGI-3 was built with testing and model auditing in mind. Each AI run is recorded along with its reasoning traces. We’ve had over 1,000,000 games played on ARC-AGI-3 so far.
For this analysis we:
- Download all the logs/reasoning/steps from every public game run for GPT-5.5 and Opus 4.7
- Write a strategy for each game to serve as our ground truth answer
- Ask Codex/Claude Code to analyze the reasoning steps against the level strategy to find failure modes
- Do a meta-analysis across games for a single model. Repeat the meta-analysis across models.
- Validate findings, by hand, with a human
This led us to discover why each model passed/failed, which failure modes were shared and which were unique to each model.
Failure mode 1: true local effect, false world model
The first failure mode we saw was the most dominant pattern. Models were able to perceive a local effect:
When I press ACTION3, this object rotates.
but they weren’t able to translate that into a world model:
ACTION3 rotates the object, and rotation controls which side gets a new value, so I should orient the object to match the target before acting.
Put another way, the models don’t fail because they don’t observe anything...they fail because they can't anchor their observation in a world model.
For example, Opus, when playing cd82, knew that ACTION3 rotated the container by step 4, and by step 6 it saw ACTION5 pour/dip paint but it never converted that into "orient bucket, then dip to recreate the top-left target."

Opus 4.7 Playing
cd82. Game Score: 0%Or in cn04, Opus found a successful rotate-then-place interaction (this is the correct hypothesis, step 23) but optimized for whole-shape overlap (incorrect) and fake top-row progress (step 60).

cn04. Game Score: 0%Failure mode 2: wrong level of abstraction from training data
The second failure mode came from an incorrect level of abstraction from a model’s training data. Across the runs, the models repeatedly explained unfamiliar mechanics by mapping them to known games: Tetris, Frogger, Sokoban, Powder Toy, Flood-It, MiniGrid, CoinRun, Breakout, Pong, Boulder Dash, and others. While recalling abstractions from core prior knowledge is helpful in theory, the literal analogies from the model’s training data hijacked action selection.
The problem is that a local visual resemblance becomes a full gameplay theory, then the model wastes actions testing the wrong affordances.
In cd82, GPT-5.5 anchored on sand/physics/Flood-It mechanics. ls20 became Breakout instead of key combinations.

ls20 for other games. GPT-5.5 Playing ls20. Game Score: 0%Failure mode 3: solved the level, didn’t learn the game
The final failure mode we saw was that even if a model beat a level, that reward did not translate into further success. This shows us that beating a level is not the same as understanding it.
Two Opus runs make this especially clear. On ka59, Opus solved Level 1 in 37 actions, but its working theory of the click (teleporting the active character) was wrong. Although it looked like a clean win, this was a coincidence between a misread primitive and a forgiving level.
When Level 2 demanded the real mechanic (shape-matching and pushing), Opus’s mislabel theory hardened into "click each target to fill it," and the run never recovered.

ka59. Game Score: 2.04%ar25 shows the same pattern at a different abstraction level. Opus cleared Level 1 with a correct read of mirrored movement (step 4), then in Level 2 actually discovered the new movable-axis mechanic (step 227), but it still drifted into hallucinated rules of punching holes and needing a flip.
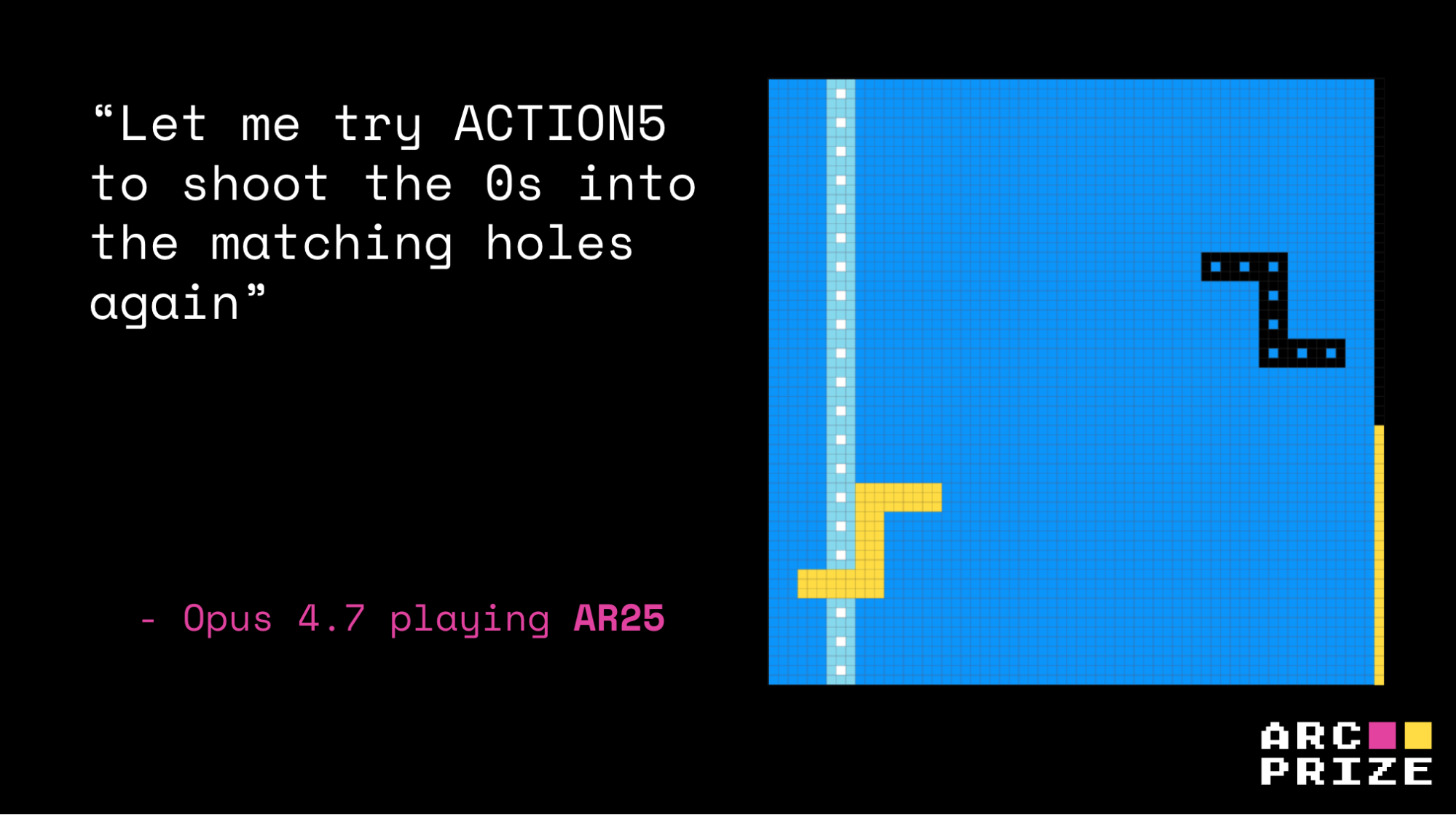
ar25. Game Score: 0.15%In both cases the Level 1 success masked a missing or distorted primitive, and the partial win became a confident scaffold for the wrong Level 2 strategy.
This also shows us that early level progression can be a noisy signal of comprehension. Without an explicit check on why the prior level was won, models will carry their misconception into the next level.
Opus 4.7: wrong compression, GPT-5.5: failure to compress
As we compare the runs of GPT-5.5 and Opus 4.7 we’re able to see they failed in different ways. This is important because aggregate scores alone would hide this distinction.
Opus had the wrong compression, GPT-5.5 failed to compress.
Opus 4.7 is stronger at short-horizon mechanic discovery. On ar25 it identifies the mirror structure almost immediately and clears Level 1. On ka59 it reads the two-character, two-target layout and executes the short Level 1 sequence even with an incomplete world model.
The flipside is that Opus is also more likely to latch onto a false invariant and execute it aggressively. On cn04 it leans into a fake progress/timer/conversion theory and spends the opener click-fishing inside that story (step 60). It does form a working theory, it's just the wrong one.
GPT-5.5 sits at the other end. Its hypothesis generation is wider, which makes it more likely to articulate the right idea but less likely to turn it into a plan. On ar25 it names the mirror effect but keeps reopening the genre space, drifting through Tetris, Frogger, Pong, and Tower of Hanoi instead of committing to reflection. On ka59 it reaches the correct object ontology, two target outlines and a switchable second character, but never commits to it.
The difference comes down to compression. Opus compressed its observations into a confident-but-wrong theory. GPT-5.5 had difficulty compressing at all.
ARC-AGI-3 measures agent autonomy
Each ARC-AGI-3 environment has been solved by at least two humans without special training. What makes them hard for agents is that they require something closer to real intelligence through encountering an unfamiliar environment, forming a working theory, testing it, updating it when the evidence disagrees, and carrying forward what was learned.
That same level of meta-learning is also what real-world agents will need.
Real-world agents will not just operate inside clean benchmark prompts or memorized task templates. They will face unfamiliar websites, internal tools, dashboards, forms, APIs, workflows, and edge cases that were not described in advance. In those settings, failure will often look exactly like the failure modes in ARC-AGI-3.
That's why ARC Prize Foundation will continue auditing every major frontier release. Scores tell you what a model achieved. Replays tell you whether or not the reasoning is likely to generalize.
If you’d like to help us audit the frontier of AI with ARC-AGI-3, come join the team.
Analysis notes
- With our default tests, GPT-5.5 did not return its reasoning traces. The qualitative analysis above therefore uses an
analysis moderun, which is an alternate testing setup intended to elicit more explicit descriptions of how the model is interpreting the environment and deciding what to try next. The official GPT-5.5 score is not from that mode. All reported scores use the standard ARC-AGI-3 harness, matching the setup used for Opus 4.7.