
ARC Prize 2025 Results & Analysis
Year of the Refinement Loop
We've officially wrapped Year 2 of ARC Prize! While the Grand Prize remains unclaimed, we're excited to announce the ARC Prize 2025 Score and Paper winners and share new analysis on AGI progress based on ARC-AGI in 2025.

Competition Progress
First, the Kaggle competition results. In total, 1,455 teams submitted 15,154 entries for ARC Prize 2025 - nearly identical to ARC Prize 2024. The top Kaggle score winner reached a new SOTA on the ARC-AGI-2 private dataset of 24% for $0.20/task.
We also had 90 papers submitted, up from 47 last year – and many of them are impressively strong! Due to the exceptional quality, we decided to expand the paper prizes to include 5 additional runners-up and recognize 8 additional honorable mentions.
We are proud to say: all ARC Prize 2025 winning solutions and papers are open-source.
Industry Progress
We've seen material progress in 2025 on ARC-AGI-2 from commercial frontier AI systems and bespoke model refinement solutions. As of today, the top verified commercial model, Opus 4.5 (Thinking, 64k), scores 37.6% for $2.20/task. The top verified refinement solution, built on Gemini 3 Pro and authored by Poetiq, scores 54% for $30/task.
Over the past year, ARC-AGI has been reported on model cards by all 4 major AI labs to benchmark frontier AI reasoning: OpenAI, xAI, Anthropic, and Google DeepMind.
In 2024, the ARC-AGI benchmark pinpointed the arrival of "AI reasoning systems" and drove early explanatory analysis. We're only one year into the deployment of AI reasoning systems, a new technology we consider on par with the invention of LLMs. ARC has helped us understand the capabilities and pace of scaling this new paradigm.
Now in 2025, ARC-AGI is being used to demonstrate "refinement loops". From an information theory perspective, refinement is intelligence. While we still need new ideas to achieve AGI, ARC has catalyzed several now open-source refinement approaches (documented below). I anticipate these will push AI reasoning further in 2026.
And now, let's meet the winners of this year's competition progress prizes.
ARC Prize 2025 Winners
High Scores
| Place | Prize | Team | ARC-AGI-2 Private Eval Score | Sources |
|---|---|---|---|---|
| 1st | $25k | NVARC | 24.03% | Code | Paper | Video |
| 2nd | $10k | the ARChitects | 16.53% | Code | Paper | Video |
| 3rd | $5k | MindsAI | 12.64% | Code | Paper | Writeup | Video |
| 4th | $5k | Lonnie | 6.67% | Code | Paper |
| 5th | $5k | G. Barbadillo | 6.53% | Code | Paper |
Paper Awards
| Place | Prize | Authors | Title |
|---|---|---|---|
| 1st | $50k | A. Jolicoeur-Martineau | Less is More: Recursive Reasoning with Tiny Networks (paper, interview) |
| 2nd | $20k | J. Pourcel, C. Colas & P. Oudeyer | Self-Improving Language Models for Evolutionary Program Synthesis: A Case Study on ARC-AGI (paper, video) |
| 3rd | $5k | I. Liao & A. Gu | ARC-AGI Without Pretraining (paper, video) |
| Runner Up | $2.5k | I. Joffe & C. Eliasmith | Vector Symbolic Algebras for the Abstraction and Reasoning Corpus (paper) |
| Runner Up | $2.5k | J. Berman | From Parrots to Von Neumanns: How Evolutionary Test-Time Compute Achieved State-of-the-Art on ARC-AGI (paper) |
| Runner Up | $2.5k | E. Pang | Efficient Evolutionary Program Synthesis (paper) |
| Runner Up | $2.5k | E. Guichard, F. Reimers, M. Kvalsund, M. Lepperød & S. Nichele | ARC-NCA: Towards Developmental Solutions to the Abstraction and Reasoning Corpus (paper) |
| Runner Up | $2.5k | M. Ho et al. | ArcMemo: Abstract Reasoning Composition with Lifelong LLM Memory (paper) |
Honorable Mentions
| Authors | Title |
|---|---|
| K. Hu et al. | ARC-AGI is a Vision Problem! (paper) |
| D. Franzen, J. Disselhoff & D. Hartmann | Product of Experts with LLMs: Boosting Performance on ARC Is a Matter of Perspective (paper, interview) |
| G. Barbadillo | Exploring the combination of search and learn for the ARC25 challenge (paper) |
| A. Das, O. Ghugarkar, V. Bhat & J. McAuley | Beyond Brute Force: A Neuro-Symbolic Architecture for Compositional Reasoning in ARC-AGI-2 (paper) |
| R. McGovern | Test-time Adaptation of Tiny Recursive Models (paper) |
| P. Acuaviva et al. | Rethinking Visual Intelligence: Insights from Video Pretraining (paper) |
| J. Cole & M. Osman | Don't throw the baby out with the bathwater: How and why deep learning for ARC (paper, interview) |
| I. Sorokin & Jean-François Puget | NVARC solution to ARC-AGI-2 2025 (paper) |
The Refinement Loop
The central theme driving AGI progress in 2025 is refinement loops. At its core, a refinement loop iteratively transforms one program into another, where the objective is to incrementally optimize a program towards a goal based on a feedback signal.
Two examples come from Evolutionary Test-Time Compute (J. Berman) and Evolutionary Program Synthesis (E. Pang). Berman's approach drives an evolutionary search harness evolving an ARC solution program in natural language. Pang's approach does the same, but in Python, and dynamically creates a program abstraction library to steer synthesis.
In both cases, the approaches go through a two-phase refinement process. First, it explores (generates many candidate solutions) and then verifies (programs are analyzed to yield a feedback signal). This is repeated per-task in a loop until the final resulting program is fully refined and gives an accurate answer to all the training input/output pairs.
Zero-Pretraining Deep Learning Methods
Refinement loops are becoming the basis for a new type of training for deep learning models.
Classically, deep learning models are trained on input/output pairs using gradient descent to create a static neural network. This training algorithm gradually refines a high-dimensional curve in the network's latent space. Then at inference-time, when presented with a new input, the network does forward passes to approximate the output based along this curve. This basic concept, coupled with test-time adaptation and data augmentation, is responsible for the top score in ARC Prize 2024 (ARChitects) and 2025 (NVARC).
We're now seeing early success with a very different training approach that directly trains neural weights to represent a task-solving program. Input/output pairs are still used as a ground truth and refinement loops play a key role in training, mirroring program synthesis approaches – but in weights space this time.
This approach has 2 unusual properties:
- The resulting networks are extremely small for their relative ARC-AGI performance.
- All the material task-specific training happens at test-time.
Open Source Examples
Tiny Recursive Model (TRM)
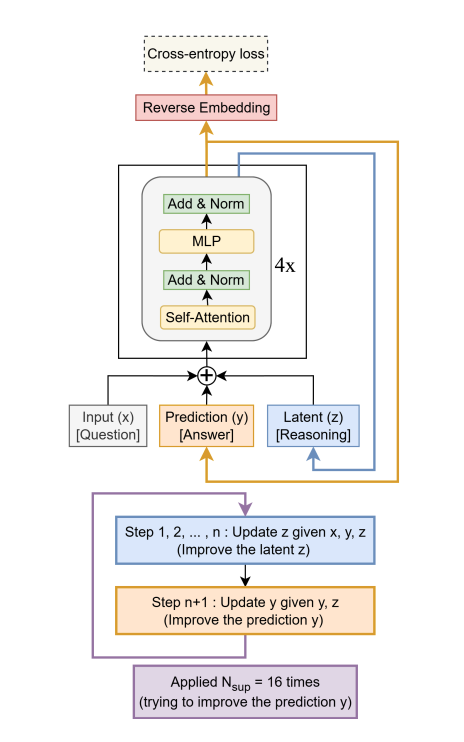
For example, the Tiny Recursive Model (TRM) (Paper Award 1st Place, Alexia Jolicoeur-Martineau), which built upon earlier Hierarchical Reasoning Model (HRM) work, was able to achieve 45% test-accuracy on ARC-AGI-1 and 8% on ARC-AGI-2 with only 7M parameter network. From the paper:
TRM recursively improves its predicted answer
ywith a tiny network. It starts with the embedded input questionxand initial embedded answery, and latentz. For up toNsup = 16improvement steps, it tries to improve its answery. It does so by i) recursively updatingntimes its latentzgiven the questionx, current answery, and current latentz(recursive reasoning), and then ii) updating its answerygiven the current answeryand current latentz. This recursive process allows the model to progressively improve its answer (potentially addressing any errors from its previous answer) in an extremely parameter-efficient manner while minimizing overfitting.
CompressARC
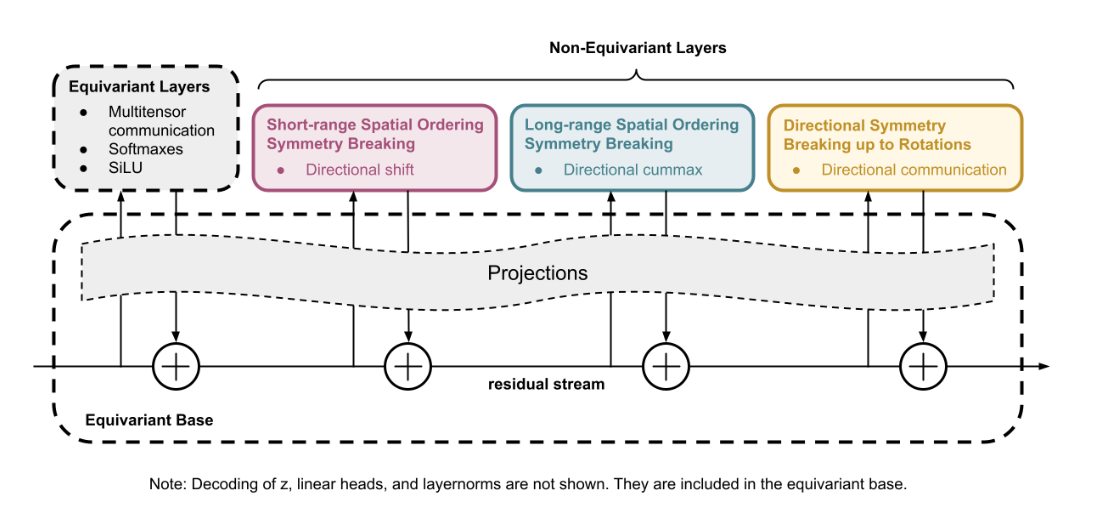
Another novel example is CompressARC (Paper Award 3rd Place, Isaac Liao), which introduces only 76K parameters, yet achieves 20% on the ARC-AGI-1 evaluation set processing each puzzle in roughly 20 minutes on 1 RTX 4070.
This solution features:
- No pretraining. Models are randomly initialized and test-time trained.
- No dataset. One model trains on just one target task and outputs one answer.
- No branching search. Just gradient descent.
The method works by minimizing the description length (an MDL principle) of each task at test time. Liao derives how a typical Variational Autoencoder (VAE) loss with decoder regularization can be used in place of combinatorial search to refine very tiny neural network programs. The generalization results from such a tiny network are impressive.
Commercial Examples
We also have evidence of iterated "refinement" in commercial AI reasoning systems. A chain-of-thought can be interpreted as a natural language program transforming one latent state into another.
Consider ARC-AGI task #4cd1b7b2. Gemini 3 Pro used 96 reasoning tokens to solve vs. Gemini 3 Deep Think's 138,000. Higher reasoning modes for these systems are strongly correlated with more reasoning tokens (longer programs) even when not strictly needed.
These longer natural language programs allow more refinement (further exploration and verification).
Here are some examples reasoning analysis outputs we've seen in practice.
… which fails the complete set requirement. This suggests the current solution might not fully satisfy the puzzle's constraints. I need to re-examine the box configuration and explore alternative arrangements … (Claude Opus 4.5)
… which suggests further investigation is needed to complete the analysis. I'll verify the center point at row 9, column 15 … (Claude Opus 4.5)
… maybe each input row is being duplicated three times in the output, but how does that fit with the rest? Wait, the third output row is … (QwQ 32B)
One new important finding with the class of frontier commercial models released late-2025 (Gemini 3, Claude Opus 4.5, …) is that you can add refinement loops at the application layer to meaningfully improve task reliability instead of relying solely on provider reasoning systems. This still requires the foundational model to have knowledge coverage of your task domain.
Model Refinements
We've added a new category to the leaderboard called Model Refinements and have verified a new Gemini 3 Pro refinement, open sourced by Poetiq, which improves performance on ARC-AGI-2 from baseline 31%, $0.81/task up to 54%, $31/task. Notably, the same model refinement achieved similar improvements on Claude Opus 4.5 with accuracy rivaling that of Gemini 3 Pro (Ref) but at approximately twice the cost per task (~$60/task), as reported by Poetiq.
Currently, refinement harnesses we're seeing are domain-specific. But with techniques like GEPA and DSPy, one can develop general-purpose reliability improvements at the application layer (so long as you have a verifier or environment capable of producing a feedback signal).
We expect these types of general refinement and harness improvements to eventually make their way "behind the API" of commercial AI systems. We also expect bleeding-edge, task-specific accuracy will keep being driven by knowledge specialization and verifiers at the application layer.
AGI Progress & the Future of ARC
As of 2025, with the advent of AI reasoning systems, task domains with the following 2 characteristics are reliably automatable – no new science needed.
- Sufficient task knowledge coverage in the foundational model
- Task provides a verifiable feedback signal
Current AI reasoning performance is tied to model knowledge.
We should take a moment to appreciate how strange this is! Human reasoning capability is not bound to knowledge, and this has all sorts of weird implications and leads us towards imprecise analogies like "jagged intelligence".
There are many pieces of supporting evidence this year, including scores from ARC-AGI-2 (static abstract reasoning), 2025 IMO Gold (math), and 2025 ICPC 100% (coding) - all being progressed by AI reasoning systems. These task domains are significantly broader than the narrow domain of the tasks that pure LLMs are useful for. But, they are still relatively narrow in the global sense.
Nonetheless, this is a profound upgrade in AI capability that emerged this year. The invention and scale up of chain-of-thought synthesis rivals the invention and scale up of transformers. And yet we are still very early. Few people have directly experienced these tools. According to OpenAI, only ~10% of ChatGPT free users have ever used "thinking" mode. And I expect diffusion of current technology (even just in business) to take 5-10 more years.
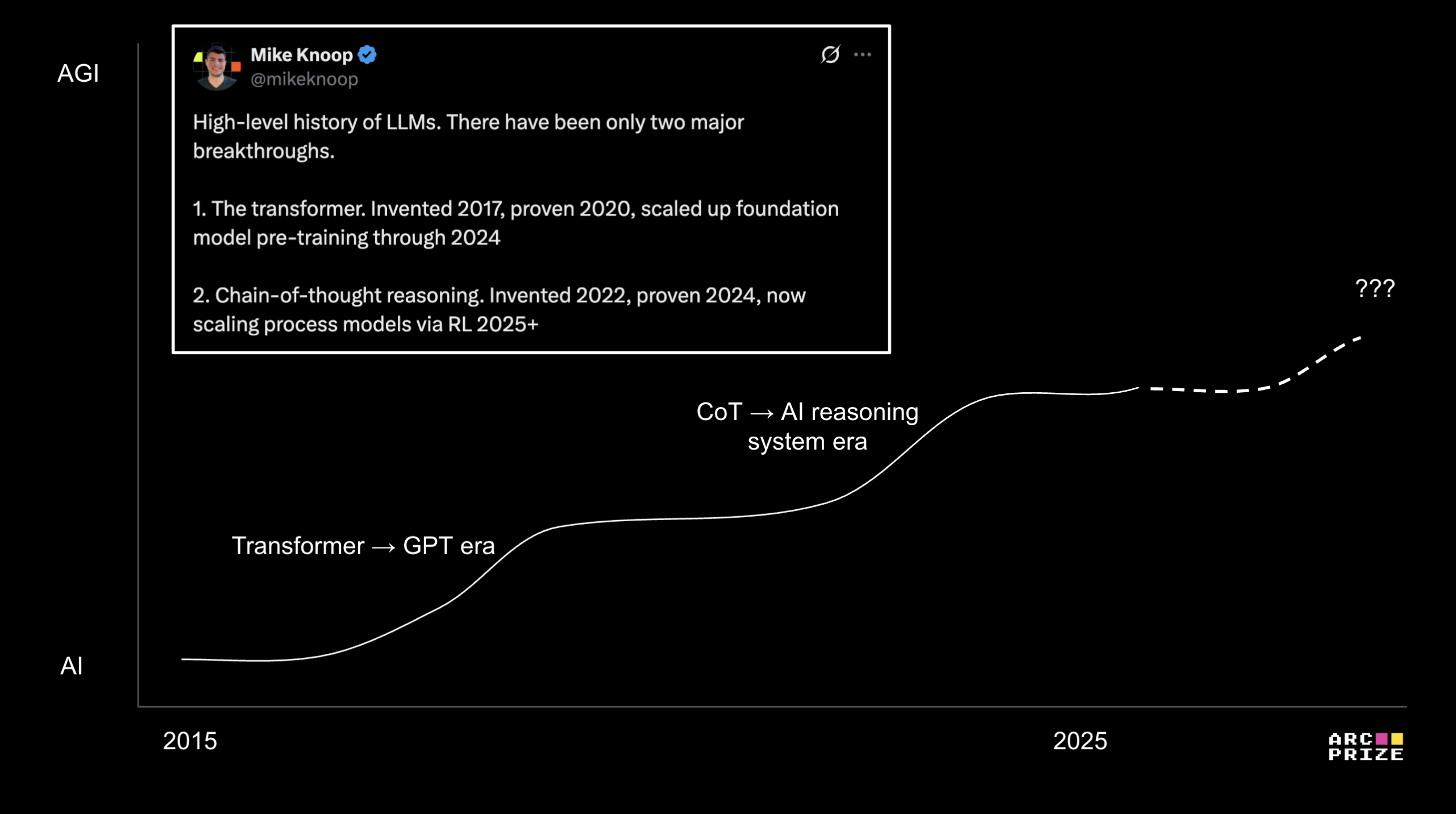
Collecting domain knowledge and building verifiers is not free. This is relatively expensive and specialized work. At the moment, AI automation is a function of societal will to invest the needed talent, compute, and data. I expect a steady drum beat of exciting new results over the next 12-24 months as society runs the global search for which problems are (1) most important and (2) fit within the cost threshold.
This includes early results where AI systems produce new scientific knowledge in fields with good knowledge coverage. Just this week, Steve Hsu published an example of an AI refinement loop using a generator-verifier to create a novel result in quantum physics.
However, many, if not most, potentially automatable problems fall beyond the societal cost cutoff today. As the engineering progresses, costs will come down, opening up more domains to automation. Bigger picture, machines that can perform highly efficient adaptation to produce paradigm-shifting innovation are still well within the realm of science fiction.
For the ARC-AGI-1/2 format, we believe the Grand Prize accuracy gap is now primarily bottlenecked by engineering while the efficiency gap remains bottlenecked by science and ideas. ARC Prize stands for open AGI progress, and, as we've previously committed, we will continue to run the ARC-AGI-2 Grand Prize competition in 2026 to track progress towards a fully open and reproducible solution.
As good as AI reasoning systems are, they still exhibit many flaws and inefficiencies necessary for AGI. We still need new ideas, like how to separate knowledge and reasoning, among others. And we'll need new benchmarks to highlight when those new ideas arrive.
Overfitting on Knowledge
There is a concept in machine learning called overfitting. Classically, this occurs when your model learns too much from training. It learns to memorize the exact data instead of learning the general patterns. This leads the model to perform poorly on unseen data at test time.
Stemming from this issue, a common AI benchmarking critique is that model providers are incentivized to "benchmark max" or cheat by "training to the test" to report high scores on benchmarks for marketing that don't generalize to real-world use cases.
ARC-AGI-1 and ARC-AGI-2 were designed to be resistant to this style of overfitting by using a private dataset for official scoring and verification.
AI reasoning systems have changed the game in a way which reflects real progress. They have demonstrated non-zero fluid intelligence and are able to adapt to tasks further away from their exact knowledge when the foundational model is grounded in the broader domain.
This means even well-designed benchmarks which resist direct memorization can now be "overfit" if the public train and private test sets are too similar (e.g., IDD) and the model was trained on a lot of public domain data.
We believe this is happening to ARC-AGI-1 and ARC-AGI-2 - either incidentally or intentionally, we cannot tell.
One bit of evidence from our Gemini 3 verification:
… Target is Green (3). Pattern is Magenta (6) Solid. Result: Magenta Square on Green … (Gemini 3 Deep Think)
Our LLM verification harness does not mention ARC tasks or color format, yet the model is using (correct!) ARC color mappings in its reasoning. This strongly suggests that ARC data is well represented in the underlying model – enough to make correct ARC inferences based on just the structure and format of 2D JSON arrays of integers.
The New Meta
While we believe this new type of "overfitting" is helping models solve ARC, we are not precisely sure how much. Regardless, the ARC-AGI-1 and ARC-AGI-2 format have provided a useful scientific canary for AI reasoning progress. But the design of benchmarks will need to adapt going forward.
In fact, there is a broader lesson that ARC Prize has taught me over the past 2 years: the most interesting and useful benchmarks are created by teams that fundamentally desire to drive progress.
To drive progress you have to seek to understand the underlying technology by devoting serious study. You have to be willing to draw attention to flaws and incentivize action. You have to adapt as the technology improves. And you have to do this year over year. Building great benchmarks requires sustained effort.
The key word is adapt. Adaptation is the core mode of intelligence. This process is not just about creating great benchmarks, it's the ultimate measure of general intelligence itself.
From Francois Chollet, last December:
You'll know AGI is here when the exercise of creating tasks that are easy for regular humans but hard for AI becomes simply impossible.
The ARC-AGI playbook: run a refinement loop by iteratvely improving benchmarks in response to AI progress in order to drive the gap between "easy for humans, hard for AI" to zero.
So, do we have AGI? Not yet. We're hard at work readying ARC-AGI-3 for release early next year and are pretty excited about the new format, we think it will require new ideas!
ARC-AGI-3
Internally, we've been fully focused on developing ARC-AGI-3 over the past 6 months. Like all versions of ARC, it is designed to be "easy for humans, hard for AI", while being the most interesting and scientifically useful benchmark to point towards AGI (and what we're still missing to unlock it). We're building hundreds of never-seen-before games.

We plan to release ARC-AGI-3 in early 2026 alongside ARC Prize 2026. This new version marks the first major format change since ARC was introduced in 2019. While the first 2 versions challenged static reasoning, version 3 is designed to challenge interactive reasoning and requires new AI capabilities to succeed.
- Exploration
- Planning
- Memory
- Goal Acquisition
- Alignment
Our early human testing and AI studies are promising. We've been incorporating lessons from ARC-AGI-2 into the design to make it as useful as possible for researchers.
Efficiency is another root concept in measuring intelligence and I'm particularly excited that the ARC-AGI-3 scoring metric will give us a formal comparison of human vs AI action efficiency (i.e., learning efficiency) for the first time.
We'll share more about ARC-AGI-3 soon. In the meantime, sign up for updates here, read more about ARC-AGI-3 here, and play the preview games here!
2025 Winner Interviews
Top Scores
A synthetic-data-driven ensemble of an improved Architects-style test-time-trained model and TRM-based components that reaches ~24% on ARC-AGI-2 under contest constraints.
A 2D-aware masked-diffusion LLM with recursive self-refinement and perspective-based scoring achieves top-tier ARC-AGI-2 performance, improving substantially over the team's 2024 autoregressive system.
A heavily engineered test-time-training pipeline that combines TTFT, augmentation ensembles, tokenizer dropout, and some new pretraining tricks to produce a competitive 15.42% ARC-AGI-2 score.
Paper Awards
Tiny Recursive Model (TRM) is a ~7M-parameter, single-network recursive model with separate answer and latent states that, via deep supervised refinement, attains ~45% on ARC-AGI-1 and ~8% on ARC-AGI-2.
SOAR is a self-improving evolutionary program synthesis framework that fine-tunes an LLM on its own search traces, boosting open-source ARC-AGI-1 solution performance up to 52% without human-engineered DSLs or solution datasets.
CompressARC is an MDL-based, single puzzle-trained neural code golf system that achieves ~20–34% on ARC-AGI-1 and ~4% on ARC-AGI-2 without any pretraining or external data.
Wrapping Up 2025
ARC Prize isn't possible without the full support of the ARC Prize team, our competition partners at Kaggle, and our sponsors. We continue to increase our ambitions and everyone has risen to meet the challenge.
I'd like to recognize the dedication of our community. In particular, we thank Mark Barney and Simon Strandgaard for their ongoing efforts to build tools, answer questions, and be a resource to the community.
Thank you to everyone across all the frontier AI labs who worked with us in 2025 to verify their new AI systems on ARC-AGI.
I also want to give a huge thank you to ARC Prize President Greg Kamradt. I'm extremely grateful he accepted the role last year. We'd be nowhere without his daily drive and persistence to make ARC better.
Special recognition to founding team member Bryan Landers, who continues to support and contribute to ARC Prize and filled in at critical moments this year.
And finally, thanks to my cofounder and ARC-AGI creator Francois Chollet for launching ARC Prize and Ndea with me.
We're inspired by everyone with new ideas who works on ARC-AGI. And we're proud of the impact ARC has had so far at the frontier of AI research. We truly believe the team that eventually builds AGI is thinking about ARC today. We'll continue to steward this attention to act as the best possible North Star towards AGI.
If you're interested in joining the ARC Prize to make an impact towards AGI see our open roles or reach out to team@arcprize.org.