
An Analysis of DeepSeek's R1-Zero and R1
R1-Zero is more important than R1
Special thanks to Tuhin and Abu from Baseten and Yuchen from Hyperbolic Labs for hosting r1-zero for us. Hardly any providers are hosting this model variant, and its availability is important for research purposes.
ARC Prize Foundation’s goal is to define, measure, and inspire new ideas towards AGI. To this end, we strive to create the strongest global innovation environment possible.
We do not have AGI yet and are still innovation constrained – scaling up pure LLM pretraining is not the path, despite this being the dominant AI industry narrative and mainstream public view as of last summer.
The reason narratives are important is they end up driving economic activity, like investment, research focus, funding, geopolitics, trade, etc. For example, in 2023-24 there was ~$20B invested into new LLM startups compared to only ~$200M into new AGI startups.
We launched ARC Prize 2024 last June to grow awareness of limits of scaling LLMs and promote a useful benchmark, ARC-AGI-1, towards a new direction that requires AI systems to adapt to novel, unseen problems instead of being able to rely strictly on memorization.
Last week, DeepSeek published their new R1-Zero and R1 “reasoner” systems that is competitive with OpenAI’s o1 system on ARC-AGI-1. R1-Zero, R1, and o1 (low compute) all score around 15-20% – in contrast to GPT-4o’s 5%, the pinnacle of years of pure LLM scaling. Based on this week’s US market reaction, the public is starting to understand the limits of scaling pure LLMs too. However, there is still broad public ignorance about impending inference demand.
In December 2024, OpenAI announced a new breakthrough o3-preview system that we verified. It scored 76% in a low compute mode and 88% in a high compute mode. The o3 system demonstrates the first practical, general implementation of a computer adapting to novel unseen problems.
Despite being huge tech news, o3-preview beating ARC-AGI-1 went largely unnoticed and unreported by mainstream press.
This is an incredibly important moment for the field of AI and for computer science and these systems demand study. But due to the closed nature of o1/o3, we’re forced to rely on speculation. Thanks to ARC-AGI-1 and now (nearly) open source R1-Zero and R1, we can add to our understanding. In particular, R1-Zero is significantly more important than R1.
“Nearly” because DeepSeek did not publish a reproducible way to generate their model weights from scratch
R1-Zero removes the human bottleneck
In our o1 and o3-preview analysis, we speculated how these reasoning systems work. The key ideas:
- Generate chains-of-thought (CoT) for a problem domain.
- Label the intermediary CoT steps using a combination of human experts (“supervised fine tuning” or SFT) and automated machines (“reinforcement learning” or RL).
- Train base model using (2).
- At test time, iteratively inference from the process model.
Techniques used to iterative sample, along with ARC-AGI-1 scores, are reviewed below:
| System | ARC-AGI-1 | Method | Avg Tokens | Avg Cost |
|---|---|---|---|---|
| r1-zero | 14% | No SFT / no search | 11K | $.11 |
| r1 | 15.8% | SFT / no search | 6K | $.06 |
| o1 (low) | 20.5% | SFT / no search | 7K | $.43 |
| o1 (med) | 31% | SFT / no search | 13K | $.79 |
| o1 (high) | 35% | SFT / no search | 22K | $1.31 |
| o3-preview (low) | 75.7% | SFT / search + sampling | 335K | $20 |
| o3-preview (high) | 87.5% | SFT / search + sampling | 57M | $3.4K |
Note: ARC-AGI-1 semi-private score shown.
With DeepSeek’s new published research, we can better inform our speculation. The key insight is that higher degrees of novelty adaptation (and reliability) for LLM reasoning systems are achieved along three dimensions:
- Adding human labels aka SFT to CoT process model training
- CoT search instead of linear inference (parallel per-step CoT inference)
- Whole CoT sampling (parallel trajectory inference)
Item (1) is bottlenecked by human data generation and constrains which domains these reasoning systems benefit most. For example, the MMLU professional law category is surprisingly much lower than the math and logic on o1.
Items (2) and (3) are bottlenecked by efficiency. o1 and o3 both show logarithmic improvement in benchmark accuracy on ARC-AGI-1 as they spend more inference compute at test time, while the different ways to spend that compute adjust the x-axis of the curve.
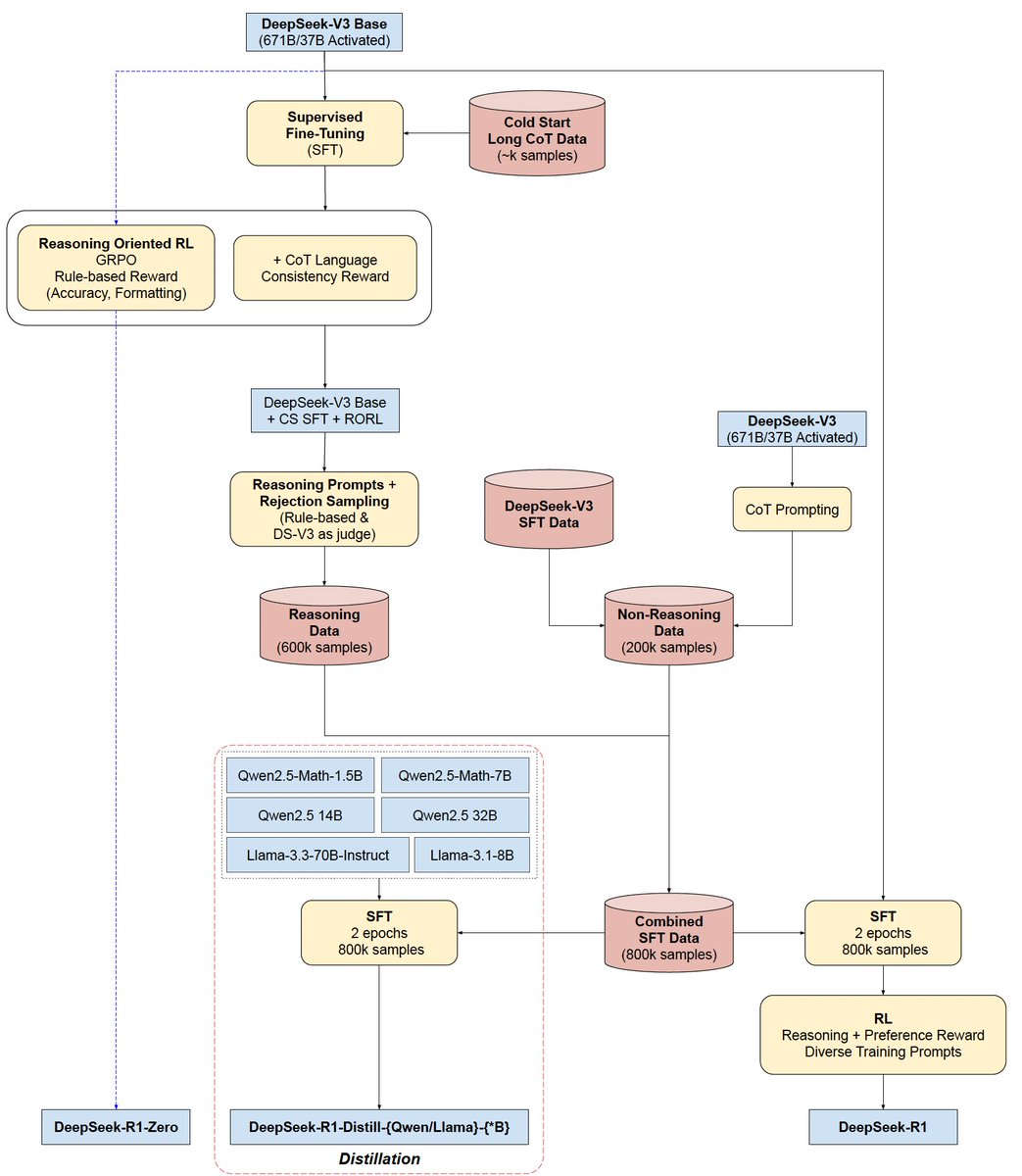
In my opinion, the most interesting thing DeepSeek has done is to publish R1-Zero separately. R1-Zero is a model which does not use SFT, the (1) item. Instead it relies purely on reinforcement learning.
R1-Zero and R1 show strong score agreement on ARC-AGI-1, scoring 14% and 15% respectively. DeepSeeks’s own reported benchmark scores also show strong agreement between R1-Zero and R1, eg. on MATH AIME 2024 scores are 71% and 76% respectively (up from ~40% on the base DeepSeek V3).
In the paper, R1-Zero authors say “DeepSeek-R1-Zero encounters challenges such as poor readability, and language mixing” and has been corroborated online. However in our testing, we found little to no evidence of incoherence when testing R1-Zero on ARC-AGI-1 which is similar to the math and coding domains the system was RL’d on.
Taken together, these findings suggest:
- SFT (eg. human expert labeling) is not necessary for accurate and legible CoT reasoning in domains with strong verification.
- The R1-Zero training process is capable of creating its own internal domain specific language (“DSL”) in token space via RL optimization.
- SFT is necessary for increasing CoT reasoning domain generality.
This makes intuitive sense, as language itself is effectively a reasoning DSL. The exact same “words” can be learned in one domain and applied in another, like a program. The pure RL approach can not yet discover a broad shared vocabulary and I expect this will be a strong focus for future research.
Ultimately, R1-Zero demonstrates the prototype of a potential scaling regime with zero human bottlenecks – even in the training data acquisition itself.
Almost certainly DeepSeek has set its sights on OpenAI’s o3 system. It is important to watch whether SFT ends up being a requirement to add CoT search and sampling, or whether a hypothetical “R2-Zero” could exist along the same logarithmic accuracy vs inference scaling curve. Based on R1-Zero results, I believe SFT will not be required to beat ARC-AGI-1 in this hypothetical scaled up version.
Dollars for reliability
There are two major shifts happening in AI, economically speaking:
- You can now spend more $ to get higher accuracy and reliability
- Training $ is moving to inference $
Both are going to drive a massive amount of demand for inference and neither will curtail the demand for more compute. In fact, they will increase the demand for compute.
AI reasoning systems promise much greater returns than simply higher accuracy on benchmarks. The number one issue preventing more AI automation use (e.g. inference demand) is reliability. I’ve spoken with hundreds of Zapier’s customers trying to deploy AI agents in their businesses and the feedback is strongly consistent: “I don’t trust them yet because they don’t work reliably”.
Previously I’ve argued that progress towards ARC-AGI would result in higher reliability. The challenge with LLM agents is they need strong local domain steering to work reliably. Stronger generalization capability requires the ability to adapt to unseen situations. We’re now starting to see evidence this view is correct. And so it’s no surprise several companies are now introducing agents (Anthropic, OpenAI, Apple, …)
Agents will drive significant near-term demand inference due the reliability needs. More broadly, developers can choose to spend more compute to increase user trust in the system. More reliability does not mean 100% accuracy though – but you’d expect to be more consistently inaccurate. This is okay because users and developers can now more confidently steer behavior via prompting when accuracy is low.
{kind=link}
Problems that were impossible for computers previously now have dollar amounts attached to them. And as efficiency climbs, those dollar amounts will go down.
Inference as training
The other major shift occurring is in the provenance of data going into LLM systems for pretraining. Previously, most data was either purchased, scraped, or synthetically generated from an existing LLM (eg. distilling or augmenting).
These reasoning systems offer a new option which is to generate “real” data as opposed to “synthetic”. The AI industry uses the term synthetic to identify low quality data that is typically recycled through an LLM to boost the overall amount of training data – with diminishing returns.
But now with reasoning systems and verifiers, we can create brand new legitimate data to train on. This can either be done offline where the developer pays to create the data or at inference time where the end user pays!
This is a fascinating shift in economics and suggests there could be a runaway power concentrating moment for AI system developers who have the largest number of paying customers. Those customers are footing the bill to create new high quality data … which improves the model ... which becomes better and more preferred by users … you get the idea.
If we can break through the human expert CoT barrier and create an extremely efficient system to create new data via search/synthesis and verification, then we should expect a massive influx of compute to go into these inference systems as they quite literally get better just by inputting dollars and raw data. Eventually this type of AI training will eclipse pretraining on human generated data altogether.
Conclusion
We will continue to see market corrections as increased inference demand becomes clear. AI system efficiency is only going to drive more usage, not just due to Jevons Paradox but because new regimes of training are unlocked as efficiency increases.
With R1 being open and reproducible, more people and teams will be pushing CoT and search to the limits. This will more quickly tell us where the frontier actually lies and will fuel a wave of innovation that increases the chance of reaching AGI quickly.
Several people have already told me they plan to use R1-style systems for ARC Prize 2025 and I’m excited to see the results.
The fact that R1 is open is a great thing for the world. DeepSeek has pushed the frontier of science forward.