
ARC Prize 2024 Winners & Technical Report
Six months ago, we launched this crazy $1M experiment called ARC Prize to test an idea: are new ideas needed for AGI?
While the Grand Prize went unclaimed this year, today is a very exciting day as we announce this year's 2024 winners and publish the ARC Prize 2024 Technical Report.
In total, 1,430 teams submitted 17,789 entries for ARC Prize 2024. We're aware of at least seven well-funded startups who shifted priorities to work on ARC-AGI and heard from multiple large corporate labs who've spun up internal efforts to tackle ARC-AGI.
The SOTA on ARC-AGI-1 increased from 33% to 55.5% during the 2024 Kaggle competition. Surprisingly, progress on our secondary public leaderboard, ARC-AGI-Pub, tracked closely, despite having access to large frontier LLMs and 1000x the compute budget compared to Kaggle.
We're proud to say: all 2024 winners and papers are open source and reproducible.
2024 Winners (High Scores)
| Prize | Team Name | Private Eval Score | Sources | |
| 1 | $25k | the ARChitects | 53.5% | Code Paper |
| 2 | $10k | Guillermo Barbadillo | 40% | Code Paper |
| 3 | $5k | alijs | 40% | Code |
| 4 | $5k | William Wu | 37% | Code |
| 5 | $5k | PoohAI | 37% | Code Paper |
Note: MindsAI scored 55.5% but did not open source and was therefore not eligible to win.
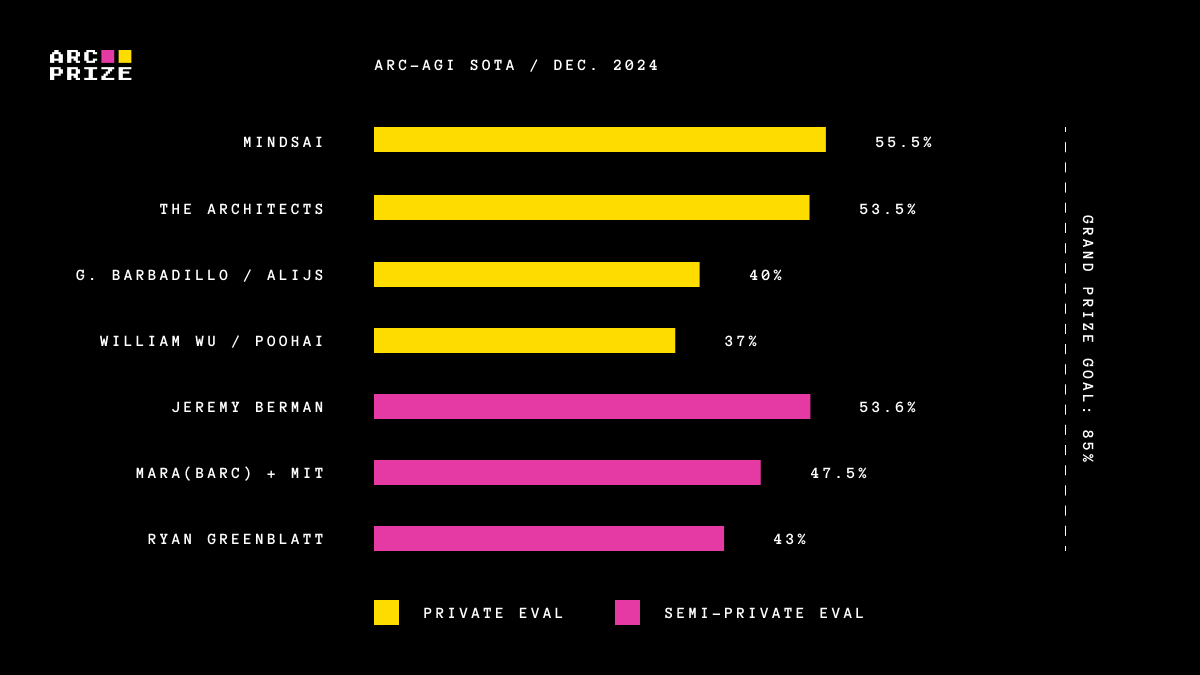
2024 ARC-AGI-Pub (High Scores)
| Name | Score (Semi-Private Eval) | Score (Public Eval) | Sources | |
| 1 | Jeremy Berman | 53.6% | 58.5% | Code Paper |
| 2 | MARA(BARC) + MIT | 47.5% | 62.8% | Code Paper |
| 3 | Ryan Greenblatt | 43% | 42% | Code Paper |
| 4 | OpenAI o1-preview (pass@1) | 18% | 21% | Code |
| 5 | Anthropic Claude 3.5 Sonnet (pass@1) | 14% | 21% | Code |
| 6 | OpenAI GPT-4o (pass@1) | 5% | 9% | Code |
| 7 | Google Gemini 1.5 (pass@1) | 4.5% | 8% | Code |
Note: No prizes were associated with ARC-AGI-Pub this year.
2024 Paper Awards
| Prize | Authors | Paper Name | Sources | |
| 1 | $50k | Li et al. | "Combining Induction and Transduction for Abstract Reasoning" | Paper |
| 2 | $20k | Akyürek et al. | "The Surprising Effectiveness of Test-Time Training for Abstract Reasoning" | Paper |
| 3 | $5k | Bonnet & Macfarlane | "Searching Latent Program Spaces" | Paper |
| Runner Up | $2.5k | Franzen et al. | "The LLM ARChitect: Solving ARC-AGI Is a Matter of Perspective" | Paper |
| Runner Up | $2.5k | Barbadillo | "Omni-ARC" | Paper |
| Runner Up | $2.5k | Fletcher-Hill | "Mini-ARC: Solving Abstraction and Reasoning Puzzles with Small Transformer Models" | Paper |
| Runner Up | $2.5k | Ouellette | "Towards Efficient Neurally-Guided Program Induction for ARC-AGI" | Paper |
| Runner Up | $2.5k | Puget | "A 2D nGPT Model For ARC Prize" | Paper |
Read more in the 2024 Technical Report
AGI Progress
When we launched ARC Prize in June 2024, progress towards AGI had stalled. Every notable commercial and open source AI system was using the same approach -- large language models built exclusively on the deep learning paradigm.
The dominant public perception from 2022 through to this summer was that LLMs would keep scaling up, with ever more training data and parameter counts, to achieve AGI. This view peaked during the large public debate over SB-1047, a California Senate bill concerning the existential risks of AI, deeply rooted in this scaling belief. SB-1047 was ultimately vetoed by Governor Newsom who (correctly, in my view) identified that innovation towards AGI is still needed.
Since then, and in part catalyzed by ARC Prize, we've seen a massive vibe shift.
In July, DeepMind published AlphaProof, and in September, OpenAI released a preview of o1. Both systems demonstrate working examples of AI systems moving beyond pure deep learning and incorporated new program synthesis, or program search, ideas. In fact, o1 represents the biggest leap in generalization power available in a commercial model since the release of GPT-2 in 2019.
We also made significant progress on ARC-AGI this year, driven by three major new categories of approaches:
-
Deep learning-guided program synthesis: Leveraging deep learning models, particularly specialized code LLMs, to generate task-solving programs or guide the program search process beyond blind brute-force methods.
-
Test-time training (TTT) for transductive models: Fine-tuning an LLM at training time on a given ARC-AGI task specification in order to recombine the prior knowledge of the LLM into a new model adapted to the task at hand.
-
Combining program synthesis together with transductive models: Merging together the two approaches above into a single super-approach, based on the observation that each approach tends to solve different kinds of tasks.
(Note: A "transductive" model is one that attempts to directly predict the output grid given a test input grid and a task specification, instead of first trying to write down a program that matches the task.)
You can learn more about these exciting approaches, as well as find reference implementations, in our ARC Prize 2024 Technical Report.
We believe AGI progress is no longer stalled. But we still need new ideas.
The fact that ARC-AGI survived five months of intense scrutiny with an outstanding $1M prize pool is strong evidence that the solution does not yet exist.
ARC Prize 2025
We've commited to running ARC Prize annually until ARC-AGI is defeated. We'll likely announce details for 2025 sometime in Q1. We have a few things in the works for next year.
Growing ARC Prize
Our mission for ARC Prize is to be a north star towards AGI. We consider 2024 a very successful experiment. To the extent a non-profit and benchmark can achieve product-market fit, we feel we've found traction. We're planning to use this momentum to turn ARC Prize into a durable foundation that can continue developing frontier AGI benchmarks to inspire future researchers.
Leaderboards
The big surprise of 2024 was how many well-funded research startups would change their roadmaps to work on beating ARC-AGI. The prize incentive system for open sourcing is not quite compatible with these types of teams (evidenced by MindsAI choosing not to share this year.) We intend to redesign our leaderboards for 2025 to best support all the different types of people and teams working on the path to discovering AGI.
ARC-AGI-2
The ARC-AGI-1 private evaluation set has been unchanged since 2019 and is not perfect.
First, The private evaluation set is small (only 100 tasks) and due to its age, there exists some risk of overfitting from the number of total submission attempts to date (on the order of 10,000.)
Second, nearly half (49%) of the private evaluation set was solved by at least one team during the original 2020 Kaggle cometition all of which were using some variant of brute-force program search. This suggests a large fraction of ARC-AGI-1 tasks are susceptible to this kind of method and does not carry much useful signal towards general intelligence.
Last, some anecdotal evidence suggests the different evaluation sets (private vs semi-private vs public) are not drawn from a consistent human difficulty distribution, which makes score comparisons across sets tricky.
We've been working in parallel this summer to address these issues and we intend to launch ARC-AGI-2 alongside the 2025 competition.
Wrapping up 2024
ARC Prize builds on the legacy of earlier ARC-AGI competitions: the 2020 competition on Kaggle as well as the 2022 and 2023 "ARCathons", which were a collaboration between François Chollet and the Davos-based non-profit AI lab, Lab42. We are grateful to the Lab42 team – Rolf Pfister, Oliver Schmid, and Hansueli Jud – for their expertise and support in facilitating a smooth transition for the ARC-AGI community. Their contributions were significant in facilitating a bigger, bolder competition and advancing initiatives like ARC-AGI-2.
We would also like to recognize the dedication of past ARCathon participants, who not only championed the benchmark but whose prior work brought new members of the community quickly up to speed. In particular, we thank Michael Hodel, Jack Cole, Mohamed Osman, and Simon Ouellette for their ongoing efforts to develop ARC-AGI solutions. Special recognition is due to Simon Strandgaard (aka neoneye) for his exceptional role as a community ambassador and prolific open-source contributor.
I want to give a huge thank you to ARC Prize leads Bryan Landers and Greg Kamradt. Without them, ARC Prize 2024 would not have succeeded.
And finally, a special thank you to my friend, Francois Chollet, for creating ARC-AGI and inspiring everyone, myself included.
We’re inspired, proud, and hopeful that ARC-AGI has played an important role in shifting attention towards new research ideas. Our belief is that the team that will eventually build AGI is thinking about ARC-AGI today, and we’re committed to stewarding this attention as a north star towards AGI.